- PROBABILITÉS (CALCUL DES)
- PROBABILITÉS (CALCUL DES)Le calcul des probabilités est certainement l’une des branches les plus récentes des mathématiques, bien qu’il ait en fait trois siècles et demi d’existence. Après s’être cantonné dans l’étude des jeux de hasard, il s’est introduit dans presque toutes les branches de l’activité scientifique, aussi bien dans l’analyse (théorie du potentiel), l’économie, la génétique (lois de Mendel), la physique corpusculaire (toutes les théories statistiques) que dans la psychologie et l’informatique, dont la source est l’étude de la quantité d’information, donnée probabiliste s’il en est. Il est rare de trouver un tel exemple de «recouvrement» dans le domaine scientifique. On peut, sans paradoxe, soutenir que toutes les mathématiques anciennes sont un cas particulier du calcul des probabilités, le certain étant de l’aléatoire dont la réalisation a une probabilité égale à 1.Le calcul des probabilités est né de l’étude des jeux de hasard. Ce dernier mot, transmis par l’Espagne, vient d’Arabie. L’arabe az-zahr , «dé à jouer», s’est transformé en azar , «hasard» (et souvent «revers») en espagnol. La base philologique, si l’on peut dire, du calcul des probabilités est donc le jeu (pile ou face, jeu de roulette, cartes). Pascal et le chevalier de Méré sont certainement les premiers à avoir voulu introduire le quantitatif dans ces études et à les mathématiser. On essaye aujourd’hui de réduire l’importance de ce point de départ en cherchant un fondement axiomatique et en enseignant le calcul des probabilités sans parler de hasard (à peine ose-t-on parler d’aléa). Il n’en est pas moins vrai que, sans l’activité des joueurs, le calcul des probabilités n’aurait sûrement pas vu le jour. Depuis le XVIIe siècle, de nombreux mathématiciens ont apporté une très importante contribution au développement de cette science: parmi les plus marquants, citons Laplace, dont le tome VII des Œuvres complètes est consacré au calcul des probabilités, et Denis Poisson, Carl Friedrich Gauss, Henri Poincaré, Émile Borel, Maurice Fréchet, Paul Levy, A. N. Kolmogorov et A. Khintchine.1. Position concrète du problèmePrenons les deux cas suivants qui concernent la réalisation d’un événement inconnu:a ) naissance d’un garçon, dans le cas de la première naissance enregistrée à l’état civil du cinquième arrondissement de Paris dans l’année 1972,b ) obtention de face dans le jet d’une pièce parfaitement symétrique.Attacher une «probabilité» à ces deux événements pose un certain nombre de questions sur lesquelles Borel s’est penché: dans le premier cas, la probabilité résulte de la connaissance détaillée et précise d’un grand nombre de phénomènes analogues; selon le langage de Borel, c’est une probabilité statistique. Dans le second exemple, la symétrie parfaite de la pièce donne autant de chances aux deux faces; on dira donc qu’il y a une chance sur deux d’obtenir face, c’est-à-dire que la probabilité de l’événement est 0,5. «Toute probabilité concrète, écrit Borel, est en définitive une probabilité statistique définie seulement avec une certaine approximation. Bien entendu, il est loisible aux mathématiciens, pour la commodité de leurs raisonnements et de leurs calculs, d’introduire des probabilités rigoureusement égales à des nombres simples, bien définis: c’est la condition même de l’application des mathématiques à toute question concrète; on remplace les données réelles, toujours inexactement connues, par des valeurs approchées sur lesquelles on calcule comme si elles étaient exactes: le résultat est approché, de même que les données» (Borel, Le Hasard ).Reprenons l’exemple de la pièce de monnaie qui permet de définir la plus simple des variables aléatoires . On a ainsi l’ensemble des valeurs prises par la variable, soitpile, face, et, la pièce étant parfaitement symétrique, la probabilité de chacune de ces valeurs est 1/2. Si l’on remplace la pièce par un dé, lui aussi parfaitement symétrique, l’égale probabilité de chacune des faces entraîne que la variable aléatoire attachée au dé aurait comme ensemble de valeursface 1, face 2, face 3, face 4, face 5, face 6, chacune des valeurs étant prise avec la probabilité 1/6. De cette façon, on a introduit l’ensemble 行 des épreuves (ou espace 行), ainsi que les probabilités attachées à chacune de ces épreuves, ces probabilités étant obtenues dans les cas expérimentaux que nous venons d’évoquer, soit par la connaissance du passé (taux de masculinité), soit par des considérations théoriques sur la nature du problème (ici, la symétrie).On peut introduire un plus grand degré de généralité en considérant que dé et pièce ne sont plus symétriques. On sera amené à donner une probabilité particulière (positive ou, à la limite, nulle) à chacune des deux faces de la pièce ou à chacune des faces du dé, la somme de ces probabilités étant égale à 1. On attribue 1 à la probabilité de l’événement certain: ici, que la pièce tombe sur pile ou sur face, que le dé tombe sur la face 1, ou la face 2, ou la face 3, ou la face 4, ou la face 5, ou la face 6. On peut supposer aussi que l’ensemble des épreuves est dénombrable; à l’épreuve d’indice i on associe la probabilité pi , avec pi 閭 0, et pi = 1. Franchissant encore une étape, on pourra supposer que l’ensemble des épreuves a la puissance du continu (par exemple Rn , ou l’espace des fonctions de carré sommable, ou l’espace des fonctions continues). Cela pose des problèmes, qui ont conduit au calcul des probabilités moderne et à l’axiomatique de Kolmogorov.2. AxiomatiqueJusqu’à présent, «probabiliser» un ensemble d’épreuves consistait à répartir, en chacun des éléments de cet ensemble, un ensemble de valeurs positives ou nulles et dont la somme était égale à 1. Ce problème ne soulevait aucune difficulté. Il n’en est pas de même quand l’espace des épreuves 行 a la puissance du continu et quand on veut associer une probabilité à chacun des sous-ensembles de 行: dans sa généralité, le problème est sans solution. On sera amené à isoler dans l’ensemble des sous-ensembles de 行 une 靖-algèbre ou tribu. Une tribu 龍 est une classe de parties de 行 possédant les propriétés suivantes:見) 龍 contient 行 et ø (ø est l’ensemble vide);廓) 龍 est stable pour les opérations de réunion, d’intersection et de passage au complémentaire, c’est-à-dire que, si les parties A et B appartiennent à une tribu, A 聆 B, A 惡 B et 璉A et 璉B (complémentaires de A et de B) en font aussi partie (cf. théorie élémentaire des ENSEMBLES);塚) 龍 est stable par rapport à la réunion dénombrable. On rapprochera cette définition de celle qui est donnée dans le chapitre 1 de l’article INTÉGRATION ET MESURE.Ces sous-ensembles s’appellent des événements . De ces axiomes on déduit que la tribu 龍 est stable par rapport aux opérations de passage à la borne supérieure, à la borne inférieure, aux limites supérieures et inférieures et aux limites dans le cas dénombrable. C’est sur cette classe 龍 de parties que l’on peut répartir une probabilité, c’est-à-dire appliquer la classe sur le segment fermé [0, 1], avec les conditions suivantes:1) la probabilité d’un événement certain est égale à 1, c’est-à-dire:
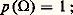 2) la probabilité est une fonction additive d’ensemble; si donc les événements A1 et A2 appartiennent à la tribu, on a:
2) la probabilité est une fonction additive d’ensemble; si donc les événements A1 et A2 appartiennent à la tribu, on a: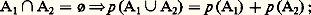 3) l’application est 靖-additive en ce sens que, si An est une suite croissante An +1 念 An d’événements dont la réunion A appartient à la tribu, alors p (An ) tend vers p (A).La classe initiale sera complétée par les ensembles p -négligeables qui sont les ensembles contenus dans ceux de la tribu qui ont une probabilité nulle. 龍 complété ainsi sera encore désigné par 龍. Le triplet ( 行, 龍, p ) a reçu le nom d’espace de probabilité . On obtient deux résultats importants qui sont l’inégalité de Boole :
3) l’application est 靖-additive en ce sens que, si An est une suite croissante An +1 念 An d’événements dont la réunion A appartient à la tribu, alors p (An ) tend vers p (A).La classe initiale sera complétée par les ensembles p -négligeables qui sont les ensembles contenus dans ceux de la tribu qui ont une probabilité nulle. 龍 complété ainsi sera encore désigné par 龍. Le triplet ( 行, 龍, p ) a reçu le nom d’espace de probabilité . On obtient deux résultats importants qui sont l’inégalité de Boole :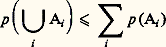 et l’égalité de Poincaré :
et l’égalité de Poincaré :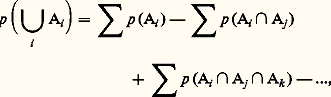 dans laquelle les différents qui figurent portent sur toutes les combinaisons possibles des indices différant les uns des autres.La définition d’une probabilité sur un espace produit s’introduit de manière naturelle. Un autre élément axiomatique est la probabilité de l’événement A conditionné par l’événement B, notée p (A/B), que l’on appelle parfois l’axiome de Bayes : La probabilité du concours de deux événements A et B (appartenant naturellement à 龍), soit A 惡 B, est égale au produit de la probabilité de B par la probabilité de A si l’événement B a lieu (ce que nous avons appelé p (A/B)); ce qui se traduit par les égalités suivantes, dans lesquelles A et B jouent un rôle symétrique:
dans laquelle les différents qui figurent portent sur toutes les combinaisons possibles des indices différant les uns des autres.La définition d’une probabilité sur un espace produit s’introduit de manière naturelle. Un autre élément axiomatique est la probabilité de l’événement A conditionné par l’événement B, notée p (A/B), que l’on appelle parfois l’axiome de Bayes : La probabilité du concours de deux événements A et B (appartenant naturellement à 龍), soit A 惡 B, est égale au produit de la probabilité de B par la probabilité de A si l’événement B a lieu (ce que nous avons appelé p (A/B)); ce qui se traduit par les égalités suivantes, dans lesquelles A et B jouent un rôle symétrique: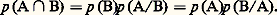 L’axiome de Bayes permet d’introduire la notion d’événements indépendants : A et B sont dits indépendants si:
L’axiome de Bayes permet d’introduire la notion d’événements indépendants : A et B sont dits indépendants si: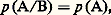 ce qui entraîne naturellement:
ce qui entraîne naturellement: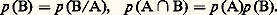 Une variable aléatoire à valeurs dans 行, est une application mesurable d’un espace de probabilité ( 行, 龍, p ) dans un espace 行1 muni d’une tribu 龍1. Un cas particulier important est celui où le doublet ( 行1, 龍1) est l’espace Rn muni de la tribu borélienne (cf. INTÉGRATION ET MESURE, chap. 3).3. Instruments de travailLois de répartitionLa fin du chapitre précédent a attiré l’attention sur le cas où ( 行1, 龍1) est l’espace Rn muni de la tribu borélienne. Dans ce cas, l’ensemble (X1, ..., Xn ) des n coordonnées d’un point constitue la variable aléatoire et l’on peut introduire une fonction de n variables x 1, ..., xn :
Une variable aléatoire à valeurs dans 行, est une application mesurable d’un espace de probabilité ( 行, 龍, p ) dans un espace 行1 muni d’une tribu 龍1. Un cas particulier important est celui où le doublet ( 行1, 龍1) est l’espace Rn muni de la tribu borélienne (cf. INTÉGRATION ET MESURE, chap. 3).3. Instruments de travailLois de répartitionLa fin du chapitre précédent a attiré l’attention sur le cas où ( 行1, 龍1) est l’espace Rn muni de la tribu borélienne. Dans ce cas, l’ensemble (X1, ..., Xn ) des n coordonnées d’un point constitue la variable aléatoire et l’on peut introduire une fonction de n variables x 1, ..., xn :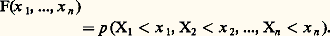 On lui donne le nom de loi de probabilité (ou fonction de répartition) de la variable aléatoire considérée. C’est une fonction non décroissante de l’ensemble des n coordonnées. Dans le cas d’une coordonnée, la fonction F(x ) non décroissante se décompose, selon le résultat classique de Lebesgue, en une somme:
On lui donne le nom de loi de probabilité (ou fonction de répartition) de la variable aléatoire considérée. C’est une fonction non décroissante de l’ensemble des n coordonnées. Dans le cas d’une coordonnée, la fonction F(x ) non décroissante se décompose, selon le résultat classique de Lebesgue, en une somme: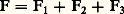 de trois fonctions non décroissantes, où 1 est la fonction des «sauts» (c’est-à-dire qu’elle est constante en dehors des points de discontinuité de F, dont l’ensemble est au plus dénombrable, et qu’elle a en ces points de discontinuité une variation, un «saut» égal à celui de F). La fonction F 漣 1, qui est donc continue, se décompose en une somme de deux fonctions non décroissantes; d’abord 3, absolument continue , c’est-à-dire égale à une intégrale de la forme suivante:
de trois fonctions non décroissantes, où 1 est la fonction des «sauts» (c’est-à-dire qu’elle est constante en dehors des points de discontinuité de F, dont l’ensemble est au plus dénombrable, et qu’elle a en ces points de discontinuité une variation, un «saut» égal à celui de F). La fonction F 漣 1, qui est donc continue, se décompose en une somme de deux fonctions non décroissantes; d’abord 3, absolument continue , c’est-à-dire égale à une intégrale de la forme suivante: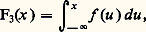 puis 2, égale naturellement à F 漣 1 漣 3, qui sera non décroissante continue mais non absolument continue; on prendra 2 telle qu’elle ne soit susceptible de variation que sur un ensemble de mesure nulle. Un exemple classique de cette dernière situation est la fonction attachée à l’ensemble triadique de Cantor: le nombre x étant compris entre 0 et 1, on l’exprime dans le système de base 3, soit:
puis 2, égale naturellement à F 漣 1 漣 3, qui sera non décroissante continue mais non absolument continue; on prendra 2 telle qu’elle ne soit susceptible de variation que sur un ensemble de mesure nulle. Un exemple classique de cette dernière situation est la fonction attachée à l’ensemble triadique de Cantor: le nombre x étant compris entre 0 et 1, on l’exprime dans le système de base 3, soit: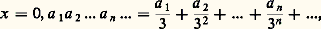 où ai est égal à 0, 1 ou 2. Considérons tous les x qui peuvent s’exprimer uniquement avec des ai égaux à 0 ou 2 (dans le cas où deux représentations sont possibles, on retiendra x si l’une des deux représentations ne comporte que des 0 ou des 2). Pour un tel x , posons:
où ai est égal à 0, 1 ou 2. Considérons tous les x qui peuvent s’exprimer uniquement avec des ai égaux à 0 ou 2 (dans le cas où deux représentations sont possibles, on retiendra x si l’une des deux représentations ne comporte que des 0 ou des 2). Pour un tel x , posons: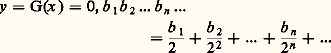 en base 2, avec bi = 0 si ai = 0 et bi = 1 si ai = 2; en dehors de l’ensemble des x considérés, la fonction G sera constante. Cette fonction est continue et ne peut pas être représentée par une intégrale, car elle n’est pas absolument continue.La décomposition F = 1 + 2 + 3 est unique; bien entendu, une ou deux des fonctions Fi peuvent être nulles.La définition:
en base 2, avec bi = 0 si ai = 0 et bi = 1 si ai = 2; en dehors de l’ensemble des x considérés, la fonction G sera constante. Cette fonction est continue et ne peut pas être représentée par une intégrale, car elle n’est pas absolument continue.La décomposition F = 1 + 2 + 3 est unique; bien entendu, une ou deux des fonctions Fi peuvent être nulles.La définition: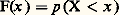 et les axiomes auxquels obéit p entraînent que F est continue à gauche, c’est-à-dire que F(x ) = F(x 漣 0). La donnée de la fonction de répartition permet de calculer la valeur de la probabilité de tous les ensembles probabilisables. C’est donc un instrument de travail essentiel.Fonction caractéristiqueParallèlement à la fonction de répartition, le calcul des probabilités utilise la fonction caractéristique, introduite par H. Poincaré, puis, sous sa forme actuelle, par P. Levy, donnée par l’intégrale de Lebesgue-Stieltjes:
et les axiomes auxquels obéit p entraînent que F est continue à gauche, c’est-à-dire que F(x ) = F(x 漣 0). La donnée de la fonction de répartition permet de calculer la valeur de la probabilité de tous les ensembles probabilisables. C’est donc un instrument de travail essentiel.Fonction caractéristiqueParallèlement à la fonction de répartition, le calcul des probabilités utilise la fonction caractéristique, introduite par H. Poincaré, puis, sous sa forme actuelle, par P. Levy, donnée par l’intégrale de Lebesgue-Stieltjes: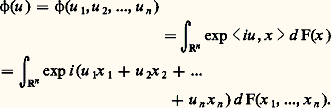 Le passage de la fonction 﨏 à la fonction F se fait par l’intermédiaire de la formule d’inversion de Fourier. Si la fonction de répartition est continue sur la frontière du pavé:
Le passage de la fonction 﨏 à la fonction F se fait par l’intermédiaire de la formule d’inversion de Fourier. Si la fonction de répartition est continue sur la frontière du pavé: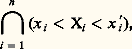 on a:
on a: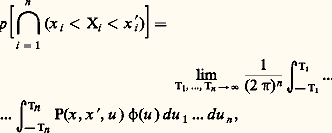 où:
où: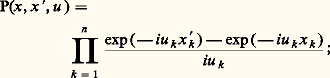 si la fonction de répartition n’était pas continue sur la frontière, cette égalité devrait subir les modifications habituelles de la théorie de la transformation de Fourier (cf. analyse HARMONIQUE).La fonction caractéristique possède plusieurs propriétés qui rendent son emploi fréquent en calcul des probabilités. La première propriété est topologique: Si une suite 1, 2, ..., Fn , ... de fonctions de répartition converge en tout point de Rn vers une fonction de répartition limite F, alors la suite 﨏1, ..., 﨏n , ... des fonctions converge, uniformément, dans tout domaine borné contenant l’origine, vers la fonction caractéristique 﨏 de F. Cet énoncé admet la réciproque suivante, souvent utilisée: Si en tout point de Rn la suite 﨏1, ..., 﨏n , ... converge vers une fonction caractéristique 﨏, alors 1, ..., Fn , ... converge vers une fonction de répartition F (sauf peut-être aux discontinuités éventuelles de F) dont 﨏 est la fonction caractéristique.La deuxième propriété, d’usage très courant également, est la suivante: Si un ensemble I =X1, ..., Xn et un ensemble J =X1 , ..., X n ont respectivement pour fonctions caractéristiques 﨏I(u 1, ..., un ) et 﨏J(u 1, ..., un ), les ensembles I et J étant indépendants , l’ensemble:
si la fonction de répartition n’était pas continue sur la frontière, cette égalité devrait subir les modifications habituelles de la théorie de la transformation de Fourier (cf. analyse HARMONIQUE).La fonction caractéristique possède plusieurs propriétés qui rendent son emploi fréquent en calcul des probabilités. La première propriété est topologique: Si une suite 1, 2, ..., Fn , ... de fonctions de répartition converge en tout point de Rn vers une fonction de répartition limite F, alors la suite 﨏1, ..., 﨏n , ... des fonctions converge, uniformément, dans tout domaine borné contenant l’origine, vers la fonction caractéristique 﨏 de F. Cet énoncé admet la réciproque suivante, souvent utilisée: Si en tout point de Rn la suite 﨏1, ..., 﨏n , ... converge vers une fonction caractéristique 﨏, alors 1, ..., Fn , ... converge vers une fonction de répartition F (sauf peut-être aux discontinuités éventuelles de F) dont 﨏 est la fonction caractéristique.La deuxième propriété, d’usage très courant également, est la suivante: Si un ensemble I =X1, ..., Xn et un ensemble J =X1 , ..., X n ont respectivement pour fonctions caractéristiques 﨏I(u 1, ..., un ) et 﨏J(u 1, ..., un ), les ensembles I et J étant indépendants , l’ensemble: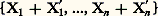 a pour fonction caractéristique:
a pour fonction caractéristique: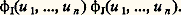 Il est donc facile d’obtenir la fonction caractéristique de la somme de deux variables aléatoires indépendantes si l’on connaît la fonction caractéristique de chacune d’elles. Avec les mêmes hypothèses, l’obtention de la fonction de répartition nécessite l’emploi du «produit de composition», ou «convolution» (cf. DISTRIBUTIONS [Mathématiques]). Si l’on pose:
Il est donc facile d’obtenir la fonction caractéristique de la somme de deux variables aléatoires indépendantes si l’on connaît la fonction caractéristique de chacune d’elles. Avec les mêmes hypothèses, l’obtention de la fonction de répartition nécessite l’emploi du «produit de composition», ou «convolution» (cf. DISTRIBUTIONS [Mathématiques]). Si l’on pose: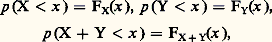 on a, pour X et Y indépendants,
on a, pour X et Y indépendants,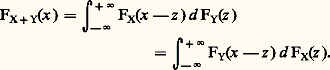 Si 行 est l’ensemble des entiers naturels N, on utilise souvent la fonction génératrice:
Si 行 est l’ensemble des entiers naturels N, on utilise souvent la fonction génératrice: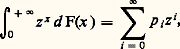 pi étant la probabilité de la valeur i . La fonction génératrice de la somme de deux variables indépendantes est encore le produit des fonctions génératrices de chacune de ces variables.Autres outilsQuelle que soit la fonction de répartition, la fonction caractéristique (et, dans le cas particulier précédent, la fonction génératrice) d’une variable aléatoire existe. Il n’en est pas toujours de même pour des nombres, appelés les moments , attachés à la loi de répartition. Le moment d’ordre p , p entier positif, est l’intégrale:
pi étant la probabilité de la valeur i . La fonction génératrice de la somme de deux variables indépendantes est encore le produit des fonctions génératrices de chacune de ces variables.Autres outilsQuelle que soit la fonction de répartition, la fonction caractéristique (et, dans le cas particulier précédent, la fonction génératrice) d’une variable aléatoire existe. Il n’en est pas toujours de même pour des nombres, appelés les moments , attachés à la loi de répartition. Le moment d’ordre p , p entier positif, est l’intégrale: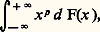 que l’on note souvent E(Xp ), espérance mathématique de Xp . Avec cette notation, la fonction caractéristique est:
que l’on note souvent E(Xp ), espérance mathématique de Xp . Avec cette notation, la fonction caractéristique est: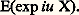 Dans tous les cas, on a:
Dans tous les cas, on a: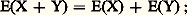 de plus, si X et Y sont indépendants, on a:
de plus, si X et Y sont indépendants, on a: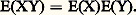 Entre les moments et la fonction caractéristique, on a la relation suivante: S’il existe un moment d’ordre p , la fonction caractéristique admet à l’origine une dérivée d’ordre p égale à:
Entre les moments et la fonction caractéristique, on a la relation suivante: S’il existe un moment d’ordre p , la fonction caractéristique admet à l’origine une dérivée d’ordre p égale à: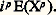 Enfin, on utilise parfois une fonction appelée fonction de concentration de Paul Levy. C’est la probabilité maximale contenue dans un intervalle fermé de longueur l , c’est-à-dire:
Enfin, on utilise parfois une fonction appelée fonction de concentration de Paul Levy. C’est la probabilité maximale contenue dans un intervalle fermé de longueur l , c’est-à-dire: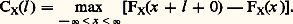 On appelle variance de X, ou carré de l’écart type, la différence:
On appelle variance de X, ou carré de l’écart type, la différence: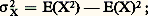 elle mesure également la dispersion de la variable aléatoire X. On appelle covariance des variables aléatoires X et Y la quantité:
elle mesure également la dispersion de la variable aléatoire X. On appelle covariance des variables aléatoires X et Y la quantité: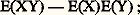 le quotient:
le quotient: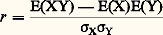 qui, d’après l’inégalité de Schwarz, est compris entre 漣 1 et + 1, s’appelle le coefficient de corrélation de X et Y. Encore que ce fait soit contesté par Fréchet, ce coefficient donne une idée de la dépendance des deux variables X et Y. D’après ce qui a été dit, si X et Y sont indépendants, r est nul; mais r peut être nul sans qu’il y ait indépendance de X et Y, ce qui justifie l’objection de Fréchet.4. Lois et fonctions cractéristiques fondamentalesVariable certaineLa première loi que l’on rencontre est la loi d’un élément certain ou presque certain. Elle correspond au cas où 諸 捻 行, la probabilité p étant telle que p (face=F0019 諸) = 1. Il en résulte que la probabilité d’un événement quelconque ne contenant pas 諸 est égale à 0. Si 行 = Rn , la fonction caractéristique de cette variable aléatoire certaine est:
qui, d’après l’inégalité de Schwarz, est compris entre 漣 1 et + 1, s’appelle le coefficient de corrélation de X et Y. Encore que ce fait soit contesté par Fréchet, ce coefficient donne une idée de la dépendance des deux variables X et Y. D’après ce qui a été dit, si X et Y sont indépendants, r est nul; mais r peut être nul sans qu’il y ait indépendance de X et Y, ce qui justifie l’objection de Fréchet.4. Lois et fonctions cractéristiques fondamentalesVariable certaineLa première loi que l’on rencontre est la loi d’un élément certain ou presque certain. Elle correspond au cas où 諸 捻 行, la probabilité p étant telle que p (face=F0019 諸) = 1. Il en résulte que la probabilité d’un événement quelconque ne contenant pas 諸 est égale à 0. Si 行 = Rn , la fonction caractéristique de cette variable aléatoire certaine est: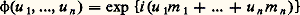 si 諸 = (m 1, ..., mn ). Des définitions du chapitre précédent il résulte qu’une variable aléatoire certaine est indépendante (au sens du calcul des probabilités ) de toute autre variable aléatoire et, en particulier, de toute variable aléatoire certaine.Variable et loi de BernoulliOn appelle variable de Bernoulli une variable pour laquelle l’ensemble image 行1 est égal à0, 1. C’est la variable utilisée dans le jeu de pile ou face (le nombre 1 étant attribué, par exemple, à face avec une probabilité p , et le nombre 0 étant attribué à pile avec la probabilité 1 漣 p = q ). Sa fonction caractéristique est q + p eiu .Loi binomialeDe la variable de Bernoulli on déduit la loi binomiale qui est la somme de n variables (indépendantes) de Bernoulli. La fonction caractéristique est:
si 諸 = (m 1, ..., mn ). Des définitions du chapitre précédent il résulte qu’une variable aléatoire certaine est indépendante (au sens du calcul des probabilités ) de toute autre variable aléatoire et, en particulier, de toute variable aléatoire certaine.Variable et loi de BernoulliOn appelle variable de Bernoulli une variable pour laquelle l’ensemble image 行1 est égal à0, 1. C’est la variable utilisée dans le jeu de pile ou face (le nombre 1 étant attribué, par exemple, à face avec une probabilité p , et le nombre 0 étant attribué à pile avec la probabilité 1 漣 p = q ). Sa fonction caractéristique est q + p eiu .Loi binomialeDe la variable de Bernoulli on déduit la loi binomiale qui est la somme de n variables (indépendantes) de Bernoulli. La fonction caractéristique est: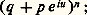 la probabilité est répartie sur l’ensemble0, 1, 2, ..., n, la probabilité de r étant Cr n p r q n size=1漣 r (probabilité de r succès sur n épreuves), le nombre Cr n étant le coefficient du binôme.Loi de Laplace-GaussLa loi de Laplace-Gauss, connue aussi sous le nom de loi normale , est celle dans laquelle 行1 = Rn , la loi de répartition de la variable n -dimensionnelle étant donnée par l’intégrale:
la probabilité est répartie sur l’ensemble0, 1, 2, ..., n, la probabilité de r étant Cr n p r q n size=1漣 r (probabilité de r succès sur n épreuves), le nombre Cr n étant le coefficient du binôme.Loi de Laplace-GaussLa loi de Laplace-Gauss, connue aussi sous le nom de loi normale , est celle dans laquelle 行1 = Rn , la loi de répartition de la variable n -dimensionnelle étant donnée par l’intégrale: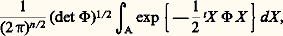 dans le cas où la variable est dite centrée , c’est-à-dire d’espérance mathématique nulle; dans cette formule:
dans le cas où la variable est dite centrée , c’est-à-dire d’espérance mathématique nulle; dans cette formule: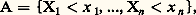 où X est la matrice colonne (vecteur) de composantes X1, ..., Xn , où tX désigne la matrice ligne transposée de la matrice colonne X et où 淋 est une matrice définie positive, dite matrice de distribution . Si cette matrice n’est pas singulière, la fonction caractéristique est:
où X est la matrice colonne (vecteur) de composantes X1, ..., Xn , où tX désigne la matrice ligne transposée de la matrice colonne X et où 淋 est une matrice définie positive, dite matrice de distribution . Si cette matrice n’est pas singulière, la fonction caractéristique est: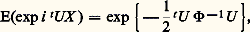 où U est la matrice colonne (vecteur) de composantes u 1, ..., un . La matrice de covariance C = (cij ), avec cij = E(Xi Xj ), est égale à 淋 size=1漣1; elle est naturellement elle aussi définie positive.Si, au lieu d’être centrée, la variable était telle que E(X ) = M , la loi de répartition serait:
où U est la matrice colonne (vecteur) de composantes u 1, ..., un . La matrice de covariance C = (cij ), avec cij = E(Xi Xj ), est égale à 淋 size=1漣1; elle est naturellement elle aussi définie positive.Si, au lieu d’être centrée, la variable était telle que E(X ) = M , la loi de répartition serait: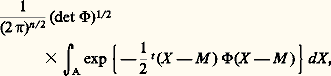 et la fonction caractéristique deviendrait:
et la fonction caractéristique deviendrait: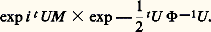 Dans le cas n = 1, on trouve, pour une variable unidimensionnelle de Laplace-Gauss non centrée, la loi de répartition:
Dans le cas n = 1, on trouve, pour une variable unidimensionnelle de Laplace-Gauss non centrée, la loi de répartition: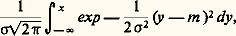 et la fonction caractéristique est:
et la fonction caractéristique est: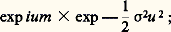 dans ces deux formules, 靖2 est la variance de cette variable.Loi de PoissonLa loi de Poisson, connue aussi sous le nom de loi des petites probabilités , est telle que 行1 = N, la probabilité attachée à l’entier n étant égale à:
dans ces deux formules, 靖2 est la variance de cette variable.Loi de PoissonLa loi de Poisson, connue aussi sous le nom de loi des petites probabilités , est telle que 行1 = N, la probabilité attachée à l’entier n étant égale à: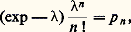 où est un paramètre positif. Bien entendu, on a:
où est un paramètre positif. Bien entendu, on a: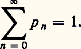 La fonction caractéristique est:
La fonction caractéristique est: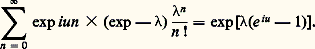 On peut utiliser ici la notion de fonction génératrice , qui est égale à exp(z 漣 1). L’espérance mathématique de la loi de Poisson de même que la variance sont égales à.Loi de CauchyL’ensemble 行1 étant ici égal à R, la loi de Cauchy est la loi de répartition:
On peut utiliser ici la notion de fonction génératrice , qui est égale à exp(z 漣 1). L’espérance mathématique de la loi de Poisson de même que la variance sont égales à.Loi de CauchyL’ensemble 行1 étant ici égal à R, la loi de Cauchy est la loi de répartition: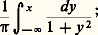 la fonction caractéristique est exp 漣 | u |. La figure 1 compare les représentations de la loi de Laplace-Gauss et de la loi de Cauchy. On est dans le cas où il n’existe aucun moment, et la fonction caractéristique n’est pas dérivable à l’origine.Loi uniformeDans le cas de la loi uniforme, 行1 est le segment [0, 1] et la probabilité d’un sous-ensemble (mesurable au sens de Lebesgue) de ce segment est égale à la mesure de Lebesgue de cet ensemble. La fonction caractéristique est ici:
la fonction caractéristique est exp 漣 | u |. La figure 1 compare les représentations de la loi de Laplace-Gauss et de la loi de Cauchy. On est dans le cas où il n’existe aucun moment, et la fonction caractéristique n’est pas dérivable à l’origine.Loi uniformeDans le cas de la loi uniforme, 行1 est le segment [0, 1] et la probabilité d’un sous-ensemble (mesurable au sens de Lebesgue) de ce segment est égale à la mesure de Lebesgue de cet ensemble. La fonction caractéristique est ici: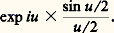 On trouvera dans les articles processus STOCHASTIQUES et STATISTIQUE d’autres lois usuelles dont des tables ont été dressées et qui sont d’usage courant.Les exemples précédents amènent à poser la question suivante: Comment savoir si une fonction est une fonction caractéristique? Il suffit évidemment que son inverse de Fourier soit une loi de répartition. C’est malheureusement une condition peu maniable et il n’en existe guère d’autre à l’heure actuelle. Signalons toutefois deux énoncés répondant à la question précédente.Théorème de Bochner . Pour qu’une fonction 﨏(u ) soit une fonction caractéristique, il faut et il suffit que 﨏(0) = 1, que 﨏 soit continue et définie positive , c’est-à-dire que l’on ait:
On trouvera dans les articles processus STOCHASTIQUES et STATISTIQUE d’autres lois usuelles dont des tables ont été dressées et qui sont d’usage courant.Les exemples précédents amènent à poser la question suivante: Comment savoir si une fonction est une fonction caractéristique? Il suffit évidemment que son inverse de Fourier soit une loi de répartition. C’est malheureusement une condition peu maniable et il n’en existe guère d’autre à l’heure actuelle. Signalons toutefois deux énoncés répondant à la question précédente.Théorème de Bochner . Pour qu’une fonction 﨏(u ) soit une fonction caractéristique, il faut et il suffit que 﨏(0) = 1, que 﨏 soit continue et définie positive , c’est-à-dire que l’on ait: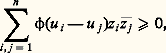 quels que soient ui , uj réels et zi , zj complexes.Théorème de Khintchine . Pour que 﨏(u ) soit une fonction caractéristique, il faut et il suffit que 﨏(u ) soit, dans tout intervalle fini, la limite uniforme d’expressions de la forme:
quels que soient ui , uj réels et zi , zj complexes.Théorème de Khintchine . Pour que 﨏(u ) soit une fonction caractéristique, il faut et il suffit que 﨏(u ) soit, dans tout intervalle fini, la limite uniforme d’expressions de la forme: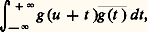 avec:
avec: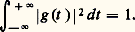 5. Arithmétique des lois de probabilitésOn désigne par l’expression arithmétique des lois de probabilités un ensemble de recherches et de résultats à l’origine desquels on relève principalement les noms de P. Levy, H. Cramer et Yu. Linnik. Les questions traitées tournent autour du problème suivant: X étant une variable aléatoire, peut-elle être décomposée comme une somme de deux variables aléatoires indépendantes X1 et X2? Il va de soi que cette décomposition est toujours possible si X1 ou X2 est une variable aléatoire certaine; on se placera donc toujours en dehors de ce cas trivial.Il convient tout d’abord de faire une remarque sur les lois définies dans le chapitre précédent. Si X1 et X2 sont toutes deux des variables de Laplace-Gauss, ou de Poisson, ou de Cauchy, et si elles sont indépendantes, leur somme est aussi respectivement de Laplace-Gauss, ou de Poisson, ou de Cauchy: c’est une conséquence de la forme des fonctions caractéristiques. Dans le cas de Laplace-Gauss, la fonction caractéristique de la somme sera de la forme:
5. Arithmétique des lois de probabilitésOn désigne par l’expression arithmétique des lois de probabilités un ensemble de recherches et de résultats à l’origine desquels on relève principalement les noms de P. Levy, H. Cramer et Yu. Linnik. Les questions traitées tournent autour du problème suivant: X étant une variable aléatoire, peut-elle être décomposée comme une somme de deux variables aléatoires indépendantes X1 et X2? Il va de soi que cette décomposition est toujours possible si X1 ou X2 est une variable aléatoire certaine; on se placera donc toujours en dehors de ce cas trivial.Il convient tout d’abord de faire une remarque sur les lois définies dans le chapitre précédent. Si X1 et X2 sont toutes deux des variables de Laplace-Gauss, ou de Poisson, ou de Cauchy, et si elles sont indépendantes, leur somme est aussi respectivement de Laplace-Gauss, ou de Poisson, ou de Cauchy: c’est une conséquence de la forme des fonctions caractéristiques. Dans le cas de Laplace-Gauss, la fonction caractéristique de la somme sera de la forme: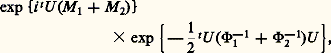 fonction caractéristique d’une loi de Laplace-Gauss ayant pour vecteur moyen la somme des vecteurs moyens et pour matrice de covariance la somme des matrices de covariance; dans le cas de Poisson, la fonction caractéristique de la somme sera:
fonction caractéristique d’une loi de Laplace-Gauss ayant pour vecteur moyen la somme des vecteurs moyens et pour matrice de covariance la somme des matrices de covariance; dans le cas de Poisson, la fonction caractéristique de la somme sera: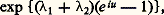 fonction caractéristique d’une loi de Poisson ayant pour paramètre la somme des paramètres des lois composantes. Dans le cas de Cauchy enfin, la fonction caractéristique de la somme sera exp漣 2 | u |, qui est la fonction caractéristique d’une loi de Cauchy à un changement d’échelle près. Il est remarquable que la réciproque de deux de ces résultats soit vraie: si X1 + X2 est une variable de Laplace-Gauss (resp. variable de Poisson) et si X1 et X2 sont indépendantes, X1 et X2 sont des variables de Laplace-Gauss (resp. variables de Poisson).Ce théorème, simple dans son énoncé, avait été pressenti dès 1934 par P. Levy qui avait indiqué certaines de ses conséquences. Il fut démontré par H. Cramer, en 1936, pour la loi de Laplace-Gauss et par D. Raikov, en 1937, pour la loi de Poisson. Le principe de la démonstration est le suivant: l’égalité X = X1 + X2, avec X1 et X2 indépendantes, entraîne l’égalité 﨏X(u ) = 﨏X1(u ) 﨏X2(u ); il s’agit donc de décomposer une fonction caractéristique de Laplace-Gauss (ou de Poisson) en un produit de deux fonctions caractéristiques, aucune de ces deux fonctions n’étant la fonction caractéristique d’une variable certaine. En utilisant des résultats de E. Picard, de É. Borel, de J. Hadamard et de S. Bernstein, on montre que cette décomposition en produit n’est possible que si X1 et X2 sont du même type que la variable initiale.On a pu aller plus loin dans ces théorèmes de décomposition en produits de fonctions caractéristiques. Posons:
fonction caractéristique d’une loi de Poisson ayant pour paramètre la somme des paramètres des lois composantes. Dans le cas de Cauchy enfin, la fonction caractéristique de la somme sera exp漣 2 | u |, qui est la fonction caractéristique d’une loi de Cauchy à un changement d’échelle près. Il est remarquable que la réciproque de deux de ces résultats soit vraie: si X1 + X2 est une variable de Laplace-Gauss (resp. variable de Poisson) et si X1 et X2 sont indépendantes, X1 et X2 sont des variables de Laplace-Gauss (resp. variables de Poisson).Ce théorème, simple dans son énoncé, avait été pressenti dès 1934 par P. Levy qui avait indiqué certaines de ses conséquences. Il fut démontré par H. Cramer, en 1936, pour la loi de Laplace-Gauss et par D. Raikov, en 1937, pour la loi de Poisson. Le principe de la démonstration est le suivant: l’égalité X = X1 + X2, avec X1 et X2 indépendantes, entraîne l’égalité 﨏X(u ) = 﨏X1(u ) 﨏X2(u ); il s’agit donc de décomposer une fonction caractéristique de Laplace-Gauss (ou de Poisson) en un produit de deux fonctions caractéristiques, aucune de ces deux fonctions n’étant la fonction caractéristique d’une variable certaine. En utilisant des résultats de E. Picard, de É. Borel, de J. Hadamard et de S. Bernstein, on montre que cette décomposition en produit n’est possible que si X1 et X2 sont du même type que la variable initiale.On a pu aller plus loin dans ces théorèmes de décomposition en produits de fonctions caractéristiques. Posons: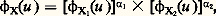 avec 見1 礪 0, 見2 礪 0. Yu. Linnik a établi que, si 﨏X(u ) est fonction caractéristique de Laplace-Gauss, il en est de même de 﨏X1(u ) et de 﨏X2(u ), et D. Dugué a montré le même résultat en remplaçant la loi de Laplace-Gauss par celle de Poisson. Enfin, Yu. Linnik a donné le théorème suivant qui regroupe tous ces résultats: dans l’égalité ci-dessus, si 﨏X(u ) est un produit d’une fonction caractéristique de Laplace-Gauss par une fonction caractéristique de Poisson, il en est de même pour 﨏X1(u ) et 﨏X2(u ).Ces résultats d’une grande élégance ne peuvent être étendus à la loi de Cauchy: on connaît des exemples où:
avec 見1 礪 0, 見2 礪 0. Yu. Linnik a établi que, si 﨏X(u ) est fonction caractéristique de Laplace-Gauss, il en est de même de 﨏X1(u ) et de 﨏X2(u ), et D. Dugué a montré le même résultat en remplaçant la loi de Laplace-Gauss par celle de Poisson. Enfin, Yu. Linnik a donné le théorème suivant qui regroupe tous ces résultats: dans l’égalité ci-dessus, si 﨏X(u ) est un produit d’une fonction caractéristique de Laplace-Gauss par une fonction caractéristique de Poisson, il en est de même pour 﨏X1(u ) et 﨏X2(u ).Ces résultats d’une grande élégance ne peuvent être étendus à la loi de Cauchy: on connaît des exemples où: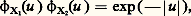 sans que 﨏X1 et 﨏X2 soient de cette forme.Ces théorèmes amorcent les recherches de décomposition: ce sont (tout au moins pour les lois de Laplace-Gauss et de Poisson) des théorèmes d’unicité. On a mis en évidence des cas d’impossibilité: il est facile d’établir qu’une variable de Bernoulli ne peut être décomposée de cette façon. Un problème particulièrement intéressant est celui des lois indéfiniment divisibles , qui a été posé et résolu par P. Levy: trouver toutes les fonctions caractéristiques 﨏(u ) telles que [ 﨏(u )] size=1見 soit également fonction caractéristique quel que soit 見 礪 0. La variable aléatoire dont 﨏(u ) est fonction caractéristique pourra alors être considérée comme une somme de variables aléatoires indépendantes «arbitrairement petites», c’est-à-dire s’écartant arbitrairement peu d’une variable certaine. Ces lois indéfiniment divisibles ont une grande importance dans l’étude des fonctions aléatoires (cf. processus STOCHASTIQUES). Pour qu’une variable aléatoire soit indéfiniment divisible, il est nécessaire et suffisant que le logarithme de sa fonction caractéristique soit de la forme:
sans que 﨏X1 et 﨏X2 soient de cette forme.Ces théorèmes amorcent les recherches de décomposition: ce sont (tout au moins pour les lois de Laplace-Gauss et de Poisson) des théorèmes d’unicité. On a mis en évidence des cas d’impossibilité: il est facile d’établir qu’une variable de Bernoulli ne peut être décomposée de cette façon. Un problème particulièrement intéressant est celui des lois indéfiniment divisibles , qui a été posé et résolu par P. Levy: trouver toutes les fonctions caractéristiques 﨏(u ) telles que [ 﨏(u )] size=1見 soit également fonction caractéristique quel que soit 見 礪 0. La variable aléatoire dont 﨏(u ) est fonction caractéristique pourra alors être considérée comme une somme de variables aléatoires indépendantes «arbitrairement petites», c’est-à-dire s’écartant arbitrairement peu d’une variable certaine. Ces lois indéfiniment divisibles ont une grande importance dans l’étude des fonctions aléatoires (cf. processus STOCHASTIQUES). Pour qu’une variable aléatoire soit indéfiniment divisible, il est nécessaire et suffisant que le logarithme de sa fonction caractéristique soit de la forme: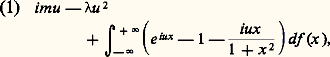 où m est un nombre réel, positif ou nul, f étant non décroissante de 漣 秊 à 0 et de 0 à + 秊 (nulle pour x = 梁 秊) et telle que l’intégrale 咽x 2 df (x ) soit finie sur tout intervalle fini. Dans ces conditions, la représentation de la fonction caractéristique d’une loi indéfiniment divisible est unique. Si f (x ) = 0, on retrouve la loi de Laplace-Gauss unidimensionnelle. Si = 0 et si f (x ) est constant, sauf pour x = 1 où f (x ) a un saut égal à k , avec m = k /2, on retrouve la loi de Poisson de paramètre k . D’une manière générale, une variable aléatoire indéfiniment divisible est la somme d’une variable certaine, d’une variable de Laplace-Gauss et d’une infinité de variables de Poisson infiniment petites, chacune de ces variables prenant l’ensemble des valeurs 0, x , 2 x , ..., nx , ..., 漣 秊 麗 x 麗 + 秊, toutes ces variables étant indépendantes entre elles.Les deux lois de Laplace-Gauss et de Poisson jouent donc un rôle fondamental dans la théorie des lois indéfiniment divisibles. On voit aisément que la loi de Cauchy est l’une de ces lois. Comme la loi de Laplace-Gauss, elle fait partie d’un sous-ensemble de l’ensemble des lois indéfiniment divisibles auxquelles Levy a donné le nom de lois stables . Ce sont les lois telles que, X1 et X2 étant deux variables indépendantes dépendant de cette loi et C1 et C2 étant deux constantes positives quelconques, on ait:
où m est un nombre réel, positif ou nul, f étant non décroissante de 漣 秊 à 0 et de 0 à + 秊 (nulle pour x = 梁 秊) et telle que l’intégrale 咽x 2 df (x ) soit finie sur tout intervalle fini. Dans ces conditions, la représentation de la fonction caractéristique d’une loi indéfiniment divisible est unique. Si f (x ) = 0, on retrouve la loi de Laplace-Gauss unidimensionnelle. Si = 0 et si f (x ) est constant, sauf pour x = 1 où f (x ) a un saut égal à k , avec m = k /2, on retrouve la loi de Poisson de paramètre k . D’une manière générale, une variable aléatoire indéfiniment divisible est la somme d’une variable certaine, d’une variable de Laplace-Gauss et d’une infinité de variables de Poisson infiniment petites, chacune de ces variables prenant l’ensemble des valeurs 0, x , 2 x , ..., nx , ..., 漣 秊 麗 x 麗 + 秊, toutes ces variables étant indépendantes entre elles.Les deux lois de Laplace-Gauss et de Poisson jouent donc un rôle fondamental dans la théorie des lois indéfiniment divisibles. On voit aisément que la loi de Cauchy est l’une de ces lois. Comme la loi de Laplace-Gauss, elle fait partie d’un sous-ensemble de l’ensemble des lois indéfiniment divisibles auxquelles Levy a donné le nom de lois stables . Ce sont les lois telles que, X1 et X2 étant deux variables indépendantes dépendant de cette loi et C1 et C2 étant deux constantes positives quelconques, on ait: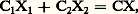 où C est une constante positive fonction de C1 et C2 et où X est une variable dépendant de la même loi. Pour ces lois, la fonction caractéristique est de la forme:
où C est une constante positive fonction de C1 et C2 et où X est une variable dépendant de la même loi. Pour ces lois, la fonction caractéristique est de la forme: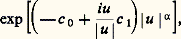 avec:
avec: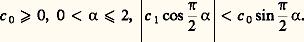 Une loi semi stable est telle que sa fonction caractéristique satisfasse à l’équation fonctionnelle:
Une loi semi stable est telle que sa fonction caractéristique satisfasse à l’équation fonctionnelle: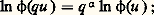 dans ce cas, le logarithme de la fonction caractéristique a pour expression:
dans ce cas, le logarithme de la fonction caractéristique a pour expression: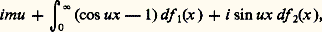 où xf 1(x ) et xf 2(x ) sont des fonctions périodiques de ln x , la seconde ayant une valeur moyenne nulle et où f 1(x ) + f 2(x ) et f 1(x ) 漣 f 2(x ) sont non décroissantes.Une loi quasi stable est telle que, si X1 et X2 sont des variables indépendantes obéissant à cette loi et si C1 et C2 sont des constantes, on ait:
où xf 1(x ) et xf 2(x ) sont des fonctions périodiques de ln x , la seconde ayant une valeur moyenne nulle et où f 1(x ) + f 2(x ) et f 1(x ) 漣 f 2(x ) sont non décroissantes.Une loi quasi stable est telle que, si X1 et X2 sont des variables indépendantes obéissant à cette loi et si C1 et C2 sont des constantes, on ait: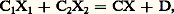 avec X obéissant à la même loi et où C et D sont des constantes. Si C = C1 + C2, le logarithme de la fonction caractéristique est:
avec X obéissant à la même loi et où C et D sont des constantes. Si C = C1 + C2, le logarithme de la fonction caractéristique est: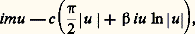 avec c 礪 0 et | 廓 | 諒 1. Si C C1 + C2, la loi quasi stable la plus générale s’obtient en ajoutant une variable certaine à une variable aléatoire dépendant d’une loi stable. P. Levy a également proposé le théorème suivant qui répond à une question posée par Khintchine: Pour qu’une loi puisse être limite de lois de variables aléatoires Sn /n , où Sn est la n -ième somme d’une série à termes aléatoires indépendants etn une suite de nombres certains tendant vers l’infini avec limn +1/n = 1, il est nécessaire et suffisant que cette loi soit indéfiniment divisible avec, dans la représentation (1) donnée ci-dessus, f (x ) pour x 麗 0 et 漣 f (x ) pour x 礪 0, fonctions convexes de ln | x | .6. Inégalités et équivalencesLa plus ancienne des inégalités utilisées en calcul des probabilités est l’inégalité de Bienaymé-Tchebychev ; si on pose:
avec c 礪 0 et | 廓 | 諒 1. Si C C1 + C2, la loi quasi stable la plus générale s’obtient en ajoutant une variable certaine à une variable aléatoire dépendant d’une loi stable. P. Levy a également proposé le théorème suivant qui répond à une question posée par Khintchine: Pour qu’une loi puisse être limite de lois de variables aléatoires Sn /n , où Sn est la n -ième somme d’une série à termes aléatoires indépendants etn une suite de nombres certains tendant vers l’infini avec limn +1/n = 1, il est nécessaire et suffisant que cette loi soit indéfiniment divisible avec, dans la représentation (1) donnée ci-dessus, f (x ) pour x 麗 0 et 漣 f (x ) pour x 礪 0, fonctions convexes de ln | x | .6. Inégalités et équivalencesLa plus ancienne des inégalités utilisées en calcul des probabilités est l’inégalité de Bienaymé-Tchebychev ; si on pose: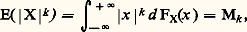 en supposant bien entendu que ce moment d’ordre k existe, on a:
en supposant bien entendu que ce moment d’ordre k existe, on a: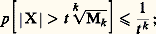 en fait, on a même, d’une manière plus précise mais moins utilisable (car la vitesse avec laquelle la limite est atteinte dépend de la loi de probabilité):
en fait, on a même, d’une manière plus précise mais moins utilisable (car la vitesse avec laquelle la limite est atteinte dépend de la loi de probabilité):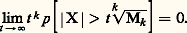 On établit de même, et c’est un résultat très utile pour l’étude des lois des grands nombres, que l’existence du k -ième moment en valeur absolue E(| X | k ) équivaut à la convergence des deux séries:
On établit de même, et c’est un résultat très utile pour l’étude des lois des grands nombres, que l’existence du k -ième moment en valeur absolue E(| X | k ) équivaut à la convergence des deux séries: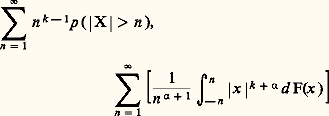 pour 見 礪 0 et k 礪 0. Dans le même ordre d’idée, si:
pour 見 礪 0 et k 礪 0. Dans le même ordre d’idée, si: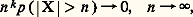 le quotient:
le quotient: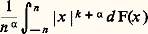 tend vers 0 pour 見 礪 0, k 閭 0. Ces inégalités conduisent à des majorations utilisées dans l’étude de «lois des grands nombres».De la définition de la variance d’une variable aléatoire on déduit facilement que la variance de la somme de n variables indépendantes est la somme des variances, d’où, en appliquant l’inégalité de Bienaymé-Tchebychev,
tend vers 0 pour 見 礪 0, k 閭 0. Ces inégalités conduisent à des majorations utilisées dans l’étude de «lois des grands nombres».De la définition de la variance d’une variable aléatoire on déduit facilement que la variance de la somme de n variables indépendantes est la somme des variances, d’où, en appliquant l’inégalité de Bienaymé-Tchebychev,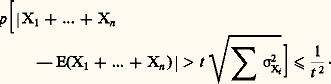 Soit maintenant X1, ..., Xn des variables (indépendantes ou non). On pose alors E(| Xi | ) = M1(i ). Considérant l’événement:
Soit maintenant X1, ..., Xn des variables (indépendantes ou non). On pose alors E(| Xi | ) = M1(i ). Considérant l’événement: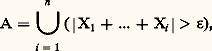 on a l’inégalité:
on a l’inégalité: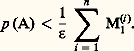 Kolmogorov a donné de ce même événement la majoration suivante:
Kolmogorov a donné de ce même événement la majoration suivante: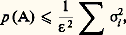 les hypothèses étant que X1, ..., Xn sont indépendantes et toutes centrées, c’est-à-dire E(Xi ) = 0 pour i = 1, ..., n , avec E(Xi 2) = 靖i 2. Ce résultat est indispensable pour démontrer la loi forte des grands nombres (ou loi presque sûre des grands nombres) ainsi que la loi du logarithme itéré due à Khintchine.Ces trois dernières inégalités supposent l’existence de moments. P. Levy a établi une inégalité portant sur la même probabilité, mais qui ne suppose l’existence d’aucun moment. Les variables aléatoires X1, ..., Xn étant indépendantes, on posera Sn = X1 + ... + Xn et on désignera par Cn la fonction de concentration de Sn (cf. chap. 3); supposons réalisée la condition suivante: les intervalles fermés de longueur égale à 﨎/2 et de probabilité maximale pour Sn , Sn 漣 Sn size=1漣 1, ..., Sn 漣 S1 ont l’origine comme point intérieur. On a alors:
les hypothèses étant que X1, ..., Xn sont indépendantes et toutes centrées, c’est-à-dire E(Xi ) = 0 pour i = 1, ..., n , avec E(Xi 2) = 靖i 2. Ce résultat est indispensable pour démontrer la loi forte des grands nombres (ou loi presque sûre des grands nombres) ainsi que la loi du logarithme itéré due à Khintchine.Ces trois dernières inégalités supposent l’existence de moments. P. Levy a établi une inégalité portant sur la même probabilité, mais qui ne suppose l’existence d’aucun moment. Les variables aléatoires X1, ..., Xn étant indépendantes, on posera Sn = X1 + ... + Xn et on désignera par Cn la fonction de concentration de Sn (cf. chap. 3); supposons réalisée la condition suivante: les intervalles fermés de longueur égale à 﨎/2 et de probabilité maximale pour Sn , Sn 漣 Sn size=1漣 1, ..., Sn 漣 S1 ont l’origine comme point intérieur. On a alors: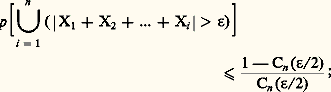 cette inégalité a permis d’établir un théorème important, dont il sera question au chapitre 8, sur la convergence des séries aléatoires.Signalons enfin une inégalité portant sur les fonctions caractéristiques:
cette inégalité a permis d’établir un théorème important, dont il sera question au chapitre 8, sur la convergence des séries aléatoires.Signalons enfin une inégalité portant sur les fonctions caractéristiques: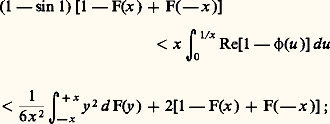 cette inégalité est utilisée au chapitre 8 pour établir le théorème sur la limite de fonctions caractéristiques.7. Topologie aléatoireLe calcul des probabilités distingue plusieurs sortes de convergences, dont la convergence en loi, la convergence en probabilité et la convergence presque sûre.Convergence en loiOn dit qu’une suite (Xn ) de variables aléatoires converge en loi vers une variable aléatoire X si les lois des Xn tendent vers la loi de X, sauf peut-être aux points de discontinuité de cette dernière. Comme on l’a vu au chapitre 3, la convergence en loi et la convergence en fonction caractéristique sont équivalentes. Cette convergence, que l’on appelle parfois aussi convergence légale et qui est analogue à la convergence vague de la théorie de la mesure, n’entraîne rien a priori sur la suite des variables Xn elles-mêmes: la suite des lois peut converger sans que la suite des variables converge (en un sens qui va être précisé).Convergence en probabilitéOn dit qu’une suite (Xn ) de variables converge en probabilité vers une variable X si:
cette inégalité est utilisée au chapitre 8 pour établir le théorème sur la limite de fonctions caractéristiques.7. Topologie aléatoireLe calcul des probabilités distingue plusieurs sortes de convergences, dont la convergence en loi, la convergence en probabilité et la convergence presque sûre.Convergence en loiOn dit qu’une suite (Xn ) de variables aléatoires converge en loi vers une variable aléatoire X si les lois des Xn tendent vers la loi de X, sauf peut-être aux points de discontinuité de cette dernière. Comme on l’a vu au chapitre 3, la convergence en loi et la convergence en fonction caractéristique sont équivalentes. Cette convergence, que l’on appelle parfois aussi convergence légale et qui est analogue à la convergence vague de la théorie de la mesure, n’entraîne rien a priori sur la suite des variables Xn elles-mêmes: la suite des lois peut converger sans que la suite des variables converge (en un sens qui va être précisé).Convergence en probabilitéOn dit qu’une suite (Xn ) de variables converge en probabilité vers une variable X si: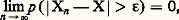 quel que soit 﨎 礪 0. Cette convergence est l’analogue de la convergence en mesure de la théorie de la mesure [cf. INTÉGRATION ET MESURE].Convergence presque sûreLa convergence presque sûre est l’analogue de la convergence presque partout en théorie de la mesure. Une suite de variables Xn converge presque sûrement (ou presque certainement) vers une variable X si:
quel que soit 﨎 礪 0. Cette convergence est l’analogue de la convergence en mesure de la théorie de la mesure [cf. INTÉGRATION ET MESURE].Convergence presque sûreLa convergence presque sûre est l’analogue de la convergence presque partout en théorie de la mesure. Une suite de variables Xn converge presque sûrement (ou presque certainement) vers une variable X si: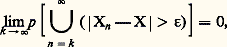 quel que soit 﨎 礪 0. En utilisant l’inégalité de Boole (cf. chap. 2), on voit que:
quel que soit 﨎 礪 0. En utilisant l’inégalité de Boole (cf. chap. 2), on voit que: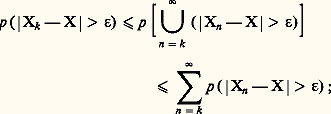 on en déduit que la convergence presque sûre entraîne la convergence en probabilité et que la convergence de la série:
on en déduit que la convergence presque sûre entraîne la convergence en probabilité et que la convergence de la série: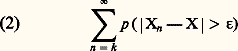 conduit à la convergence presque sûre. Si la série (2) converge, on dit parfois que la suite (Xn ) converge presque complètement sûrement vers X. Cette condition est en général plus forte que la convergence presque sûre, mais elle lui est équivalente quand les variables Xn 漣 X sont indépendantes dans leur ensemble. En effet, on a, du point de vue ensembliste,
conduit à la convergence presque sûre. Si la série (2) converge, on dit parfois que la suite (Xn ) converge presque complètement sûrement vers X. Cette condition est en général plus forte que la convergence presque sûre, mais elle lui est équivalente quand les variables Xn 漣 X sont indépendantes dans leur ensemble. En effet, on a, du point de vue ensembliste,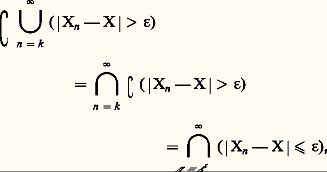 et, d’après la définition de l’indépendance, si les Xn 漣 X sont indépendants, on pourra écrire les égalités:
et, d’après la définition de l’indépendance, si les Xn 漣 X sont indépendants, on pourra écrire les égalités: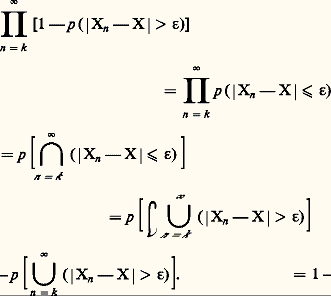 Donc, si les Xn 漣 X sont indépendants et si Xn converge presque sûrement vers X, le produit infini:
Donc, si les Xn 漣 X sont indépendants et si Xn converge presque sûrement vers X, le produit infini: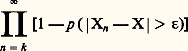 est convergent, ce qui équivaut à la convergence de la série (2), pour tout 﨎 礪 0.Comparaison des convergencesOn a donc toute une hiérarchie de convergences: la convergence presque complètement sûre implique la convergence presque sûre, laquelle implique la convergence en probabilité, celle-ci entraînant la convergence en loi (ce dernier fait s’établit facilement). Signalons que, si X est une variable certaine, la convergence en loi de Xn vers X conduit à la convergence en probabilité de Xn vers X. Si, d’autre part, tous les Xn sont des variables certaines, toutes ces convergences sont confondues au sens ordinaire de la convergence en analyse certaine. Le calcul des probabilités est donc, à ce point de vue, une extension de l’analyse certaine.Voici maintenant un mode de convergence qui est fréquemment utilisé en calcul des probabilités en raison de la très grande importance des espaces de fonctions de carré sommable. On dit qu’une suite de variables aléatoires Xn converge en moyenne quadratique vers la variable X si:
est convergent, ce qui équivaut à la convergence de la série (2), pour tout 﨎 礪 0.Comparaison des convergencesOn a donc toute une hiérarchie de convergences: la convergence presque complètement sûre implique la convergence presque sûre, laquelle implique la convergence en probabilité, celle-ci entraînant la convergence en loi (ce dernier fait s’établit facilement). Signalons que, si X est une variable certaine, la convergence en loi de Xn vers X conduit à la convergence en probabilité de Xn vers X. Si, d’autre part, tous les Xn sont des variables certaines, toutes ces convergences sont confondues au sens ordinaire de la convergence en analyse certaine. Le calcul des probabilités est donc, à ce point de vue, une extension de l’analyse certaine.Voici maintenant un mode de convergence qui est fréquemment utilisé en calcul des probabilités en raison de la très grande importance des espaces de fonctions de carré sommable. On dit qu’une suite de variables aléatoires Xn converge en moyenne quadratique vers la variable X si: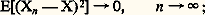 il résulte de l’inégalité de Bienaymé-Tchebychev (cf. chap. 6) que, si la suite Xn converge en moyenne quadratique vers X, alors Xn converge en probabilité vers X. La réciproque n’est pas exacte: la suite Xn peut même converger en probabilité vers X sans que les variables Xn 漣 X aient un moment d’ordre 2.On peut établir les deux théorèmes suivants, attribués à Slutsky:Théorème 1. Si une suite (Xn ) converge en probabilité vers X, on peut extraire de cette suite une suite partielle convergeant presque complètement sûrement.Théorème 2. Si une suite de variables Xn converge mutuellement en probabilité, c’est-à-dire est telle que, quel que soit 﨎 礪 0, il existe N tel que m 礪 n 礪 N entraîne p (| Xm 漣 Xn | 礪 﨎) 麗 﨎, alors il existe une variable aléatoire X telle que Xn converge en probabilité vers X.On peut se demander dans quelle mesure ces différentes convergences sont compatibles avec une norme ou une distance. La convergence presque sûre est incompatible avec une distance, et la convergence en probabilité est compatible avec une distance mais incompatible avec une norme. On utilise souvent une distance de deux variables aléatoires X et Y due à Ky-Fan: c’est la borne inférieure des x 礪 0 tels que p (| X 漣 Y | 礪 x ) 麗 x .L’historique de toutes ces notions coïncide avec l’évolution du calcul des probabilités. La notion de convergence en probabilité était connue de Bernoulli, sans avoir été explicitée par lui. Il a fallu attendre le début du XXe siècle pour dégager la notion de convergence presque sûre: elle est due essentiellement à Borel. À la même époque, Cantelli a signalé l’importance de cette acquisition. Avec juste raison, Fréchet a qualifié cette définition de «principale découverte en calcul des probabilités depuis Laplace».Il est important d’attirer l’attention sur un fait qui concerne les applications du calcul des probabilités et en particulier la statistique. La convergence en probabilité concerne la probabilité de réalisation d’un événement, probabilité qui doit tendre vers 1 pour que la convergence soit réalisée. La convergence presque sûre concerne la probabilité de réalisation d’une infinité d’éléments, alors que l’expérience ne peut fournir une infinité d’événements. Par conséquent, la convergence en probabilité sera celle du statisticien utilisateur de la statistique pour la critique de l’expérience, tandis que la convergence presque sûre sera davantage celle du théoricien du calcul des probabilités.8. Lois des grands nombres et théorème central limiteLes théorèmes qui vont être énoncés maintenant sont des applications de toutes les notions précédentes. Ils sont très utiles dans les problèmes d’estimation.Lois des grands nombresLes «lois des grands nombres» concernent des ensembles de n variables aléatoires X1, ..., Xn indépendantes, ayant même loi de probabilité (isonomes , selon un mot récemment introduit dans la terminologie); le vocabulaire anglo-saxon désigne un tel ensemble sous le nom de sample , qui signifie échantillon. On a ainsi une cascade de théorèmes de plus en plus «fins» concernant le comportement de la moyenne:
il résulte de l’inégalité de Bienaymé-Tchebychev (cf. chap. 6) que, si la suite Xn converge en moyenne quadratique vers X, alors Xn converge en probabilité vers X. La réciproque n’est pas exacte: la suite Xn peut même converger en probabilité vers X sans que les variables Xn 漣 X aient un moment d’ordre 2.On peut établir les deux théorèmes suivants, attribués à Slutsky:Théorème 1. Si une suite (Xn ) converge en probabilité vers X, on peut extraire de cette suite une suite partielle convergeant presque complètement sûrement.Théorème 2. Si une suite de variables Xn converge mutuellement en probabilité, c’est-à-dire est telle que, quel que soit 﨎 礪 0, il existe N tel que m 礪 n 礪 N entraîne p (| Xm 漣 Xn | 礪 﨎) 麗 﨎, alors il existe une variable aléatoire X telle que Xn converge en probabilité vers X.On peut se demander dans quelle mesure ces différentes convergences sont compatibles avec une norme ou une distance. La convergence presque sûre est incompatible avec une distance, et la convergence en probabilité est compatible avec une distance mais incompatible avec une norme. On utilise souvent une distance de deux variables aléatoires X et Y due à Ky-Fan: c’est la borne inférieure des x 礪 0 tels que p (| X 漣 Y | 礪 x ) 麗 x .L’historique de toutes ces notions coïncide avec l’évolution du calcul des probabilités. La notion de convergence en probabilité était connue de Bernoulli, sans avoir été explicitée par lui. Il a fallu attendre le début du XXe siècle pour dégager la notion de convergence presque sûre: elle est due essentiellement à Borel. À la même époque, Cantelli a signalé l’importance de cette acquisition. Avec juste raison, Fréchet a qualifié cette définition de «principale découverte en calcul des probabilités depuis Laplace».Il est important d’attirer l’attention sur un fait qui concerne les applications du calcul des probabilités et en particulier la statistique. La convergence en probabilité concerne la probabilité de réalisation d’un événement, probabilité qui doit tendre vers 1 pour que la convergence soit réalisée. La convergence presque sûre concerne la probabilité de réalisation d’une infinité d’éléments, alors que l’expérience ne peut fournir une infinité d’événements. Par conséquent, la convergence en probabilité sera celle du statisticien utilisateur de la statistique pour la critique de l’expérience, tandis que la convergence presque sûre sera davantage celle du théoricien du calcul des probabilités.8. Lois des grands nombres et théorème central limiteLes théorèmes qui vont être énoncés maintenant sont des applications de toutes les notions précédentes. Ils sont très utiles dans les problèmes d’estimation.Lois des grands nombresLes «lois des grands nombres» concernent des ensembles de n variables aléatoires X1, ..., Xn indépendantes, ayant même loi de probabilité (isonomes , selon un mot récemment introduit dans la terminologie); le vocabulaire anglo-saxon désigne un tel ensemble sous le nom de sample , qui signifie échantillon. On a ainsi une cascade de théorèmes de plus en plus «fins» concernant le comportement de la moyenne: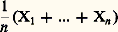 de ces n variables aléatoires.Théorème 1. Pour que ( Xi )/n converge en probabilité vers a certain, il est nécessaire et suffisant que la fonction caractéristique 﨏(u ) de la variable soit dérivable à l’origine avec a = 漣 i 﨏 (0), ce qui se traduit sur la fonction de répartition F(x ) par l’ensemble des deux conditions:
de ces n variables aléatoires.Théorème 1. Pour que ( Xi )/n converge en probabilité vers a certain, il est nécessaire et suffisant que la fonction caractéristique 﨏(u ) de la variable soit dérivable à l’origine avec a = 漣 i 﨏 (0), ce qui se traduit sur la fonction de répartition F(x ) par l’ensemble des deux conditions: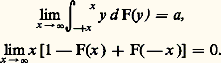 Théorème 2. Pour que ( Xi )/n converge presque sûrement vers a certain, il est nécessaire et suffisant que:
Théorème 2. Pour que ( Xi )/n converge presque sûrement vers a certain, il est nécessaire et suffisant que: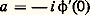 et que, de plus,
et que, de plus,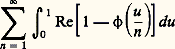 converge. Sur la fonction de répartition, ces conditions se traduisent par le fait que l’intégrale:
converge. Sur la fonction de répartition, ces conditions se traduisent par le fait que l’intégrale: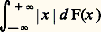 est convergente, avec:
est convergente, avec: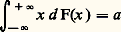 Théorème 3. Pour que ( Xi )/n converge presque complètement sûrement vers a certain, il est nécessaire et suffisant que 漣 i 﨏 (0) = a et que la fonction caractéristique ait une dérivée seconde. Pour la fonction de répartition, cela entraîne l’égalité: et la convergence de:
Théorème 3. Pour que ( Xi )/n converge presque complètement sûrement vers a certain, il est nécessaire et suffisant que 漣 i 﨏 (0) = a et que la fonction caractéristique ait une dérivée seconde. Pour la fonction de répartition, cela entraîne l’égalité: et la convergence de: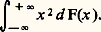 Un cas particulier important est celui de la variable de Bernoulli qui décrit une épreuve de pile ou face (cf. chap. 4). Dans ce cas, X1 + ... + Xn est le nombre aléatoire de fois où l’on aura obtenu face au cours de n épreuves et:
Un cas particulier important est celui de la variable de Bernoulli qui décrit une épreuve de pile ou face (cf. chap. 4). Dans ce cas, X1 + ... + Xn est le nombre aléatoire de fois où l’on aura obtenu face au cours de n épreuves et: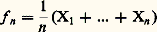 sera la fréquence de face au cours de ces n épreuves. Cette variable étant bornée, les moments de tous ordres existent et les trois théorèmes précédents peuvent s’appliquer, le nombre a étant ici égal à la probabilité p d’obtenir face. Le premier théorème signifie que l’on peut trouver N tel que, si n est supérieur à N, il y a une probabilité arbitrairement petite pour que | fn 漣 p | 礪 﨎, quel que soit 﨎 礪 0. Le deuxième implique qu’il y a une probabilité égale à 1 pour que la suite infinie des fréquences f 1, f 2, ..., fn , ... tende vers p. Enfin, le troisième indique qu’il y a encore une probabilité égale à 1 pour que la suite f 1(1), f 2(2), ..., f n (n ), ... des fréquences tende vers p , la fréquence f n (n ) étant calculée sur des «paquets» de n épreuves entièrement nouvelles pour chaque valeur de l’indice. On voit donc [cf. STATISTIQUE] que la fréquence fn peut être considérée comme une estimation de la grandeur inconnue p. Nous avons évoqué ce problème dans le chapitre 2 consacré aux bases concrètes du calcul des probabilités.Théorème central limite et loi de PoissonLe théorème central limite est un théorème de convergence en loi (cf. chap. 7). Soit encore n variables constituant un échantillon, la fonction caractéristique des variables ayant une dérivée nulle à l’origine et une dérivée seconde 﨏 (0) = 漣 靖2 (ce qui implique l’existence d’un moment d’ordre 2 égal à 靖2). La fonction caractéristique de:
sera la fréquence de face au cours de ces n épreuves. Cette variable étant bornée, les moments de tous ordres existent et les trois théorèmes précédents peuvent s’appliquer, le nombre a étant ici égal à la probabilité p d’obtenir face. Le premier théorème signifie que l’on peut trouver N tel que, si n est supérieur à N, il y a une probabilité arbitrairement petite pour que | fn 漣 p | 礪 﨎, quel que soit 﨎 礪 0. Le deuxième implique qu’il y a une probabilité égale à 1 pour que la suite infinie des fréquences f 1, f 2, ..., fn , ... tende vers p. Enfin, le troisième indique qu’il y a encore une probabilité égale à 1 pour que la suite f 1(1), f 2(2), ..., f n (n ), ... des fréquences tende vers p , la fréquence f n (n ) étant calculée sur des «paquets» de n épreuves entièrement nouvelles pour chaque valeur de l’indice. On voit donc [cf. STATISTIQUE] que la fréquence fn peut être considérée comme une estimation de la grandeur inconnue p. Nous avons évoqué ce problème dans le chapitre 2 consacré aux bases concrètes du calcul des probabilités.Théorème central limite et loi de PoissonLe théorème central limite est un théorème de convergence en loi (cf. chap. 7). Soit encore n variables constituant un échantillon, la fonction caractéristique des variables ayant une dérivée nulle à l’origine et une dérivée seconde 﨏 (0) = 漣 靖2 (ce qui implique l’existence d’un moment d’ordre 2 égal à 靖2). La fonction caractéristique de: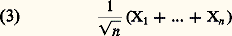 est égale à:
est égale à: sous les conditions indiquées, elle tend vers:
sous les conditions indiquées, elle tend vers: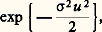 quand n augmente indéfiniment. D’après ce que l’on a vu au chapitre 3, la loi de la variable aléatoire (3) tend donc vers la loi de Laplace-Gauss:
quand n augmente indéfiniment. D’après ce que l’on a vu au chapitre 3, la loi de la variable aléatoire (3) tend donc vers la loi de Laplace-Gauss: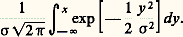 De nombreuses extensions, en particulier celle de Liapounov, ont été données à ce résultat: elles concernent des hypothèses moins restrictives sur les lois des variables Xi . Cette loi de Laplace-Gauss est d’un emploi fréquent en physique et en particulier en métrologie; on l’appelle souvent loi des erreurs : c’est la loi à laquelle obéissent les différentes mesures entachées d’erreurs d’une même grandeur. Ces erreurs sont provoquées par un très grand nombre de causes d’une importance et d’un comportement analogues, indépendantes les unes des autres. Ce raisonnement justifie la phrase attribuée à Lippmann: «Les expérimentateurs considèrent cette loi comme un résultat théorique et les théoriciens comme un fait expérimental.»La loi de Poisson peut, elle aussi, être tenue pour une loi limite. Soit n variables indépendantes de Bernoulli ayant toutes la même loi (0 avec la probabilité qn et 1 avec la probabilité pn = 1 漣 qn ). La somme de ces n variables est le nombre de succès en n épreuves; sa fonction caractéristique est:
De nombreuses extensions, en particulier celle de Liapounov, ont été données à ce résultat: elles concernent des hypothèses moins restrictives sur les lois des variables Xi . Cette loi de Laplace-Gauss est d’un emploi fréquent en physique et en particulier en métrologie; on l’appelle souvent loi des erreurs : c’est la loi à laquelle obéissent les différentes mesures entachées d’erreurs d’une même grandeur. Ces erreurs sont provoquées par un très grand nombre de causes d’une importance et d’un comportement analogues, indépendantes les unes des autres. Ce raisonnement justifie la phrase attribuée à Lippmann: «Les expérimentateurs considèrent cette loi comme un résultat théorique et les théoriciens comme un fait expérimental.»La loi de Poisson peut, elle aussi, être tenue pour une loi limite. Soit n variables indépendantes de Bernoulli ayant toutes la même loi (0 avec la probabilité qn et 1 avec la probabilité pn = 1 漣 qn ). La somme de ces n variables est le nombre de succès en n épreuves; sa fonction caractéristique est: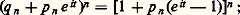 si pn tend vers 0, de telle sorte que npn tende vers, cette fonction caractéristique tend vers:
si pn tend vers 0, de telle sorte que npn tende vers, cette fonction caractéristique tend vers: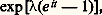 fonction caractéristique de la loi de Poisson (cf. supra ). Dans la pratique, on utilise ce résultat de la manière suivante: Sur un grand nombre n d’épreuves indépendantes avec une faible probabilité p de succès à chaque épreuve, le nombre de succès dans ces n épreuves est une variable obéissant à une loi très voisine de celle de Poisson, avec = np .Signalons maintenant une généralisation de la loi des grands nombres donnée au début de ce chapitre (et concernant la convergence presque complètement sûre). Considérons n résultats aléatoires indépendants obéissant à une même loi de probabilité F(x ). Appelons Hn (x ) la fonction en escalier égale à la fréquence sur n résultats des résultats inférieurs à x . Cette fonction très utile en statistique est appelée histogramme de fréquence (fig. 2). Cantelli a établi que la suite des Hn (x ) converge presque complètement sûrement vers F(x ). La courbe en escalier y = Hn (x ) donne donc une idée d’autant plus précise de F(x ) que n est plus grand. Mentionnons aussi la loi du logarithme itéré , déjà citée (cf. chap. 6), due à Khintchine: Soit X1, X2, ..., Xn , ... des variables aléatoires indépendantes prenant la valeur 0 avec la probabilité q et 1 avec la probabilité p = 1 漣 q ; on a l’égalité:
fonction caractéristique de la loi de Poisson (cf. supra ). Dans la pratique, on utilise ce résultat de la manière suivante: Sur un grand nombre n d’épreuves indépendantes avec une faible probabilité p de succès à chaque épreuve, le nombre de succès dans ces n épreuves est une variable obéissant à une loi très voisine de celle de Poisson, avec = np .Signalons maintenant une généralisation de la loi des grands nombres donnée au début de ce chapitre (et concernant la convergence presque complètement sûre). Considérons n résultats aléatoires indépendants obéissant à une même loi de probabilité F(x ). Appelons Hn (x ) la fonction en escalier égale à la fréquence sur n résultats des résultats inférieurs à x . Cette fonction très utile en statistique est appelée histogramme de fréquence (fig. 2). Cantelli a établi que la suite des Hn (x ) converge presque complètement sûrement vers F(x ). La courbe en escalier y = Hn (x ) donne donc une idée d’autant plus précise de F(x ) que n est plus grand. Mentionnons aussi la loi du logarithme itéré , déjà citée (cf. chap. 6), due à Khintchine: Soit X1, X2, ..., Xn , ... des variables aléatoires indépendantes prenant la valeur 0 avec la probabilité q et 1 avec la probabilité p = 1 漣 q ; on a l’égalité: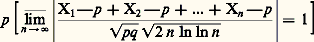 Ce théorème nécessite, pour être établi, une étude très fine de la manière dont:
Ce théorème nécessite, pour être établi, une étude très fine de la manière dont: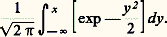 tend vers 1 et dont la loi de:
tend vers 1 et dont la loi de: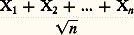 tend vers sa limite.On doit à Paul Levy un beau théorème sur la convergence des séries aléatoires, qu’il a établi en utilisant la fonction de concentration qui lui est due (cf. chap. 3). Soit X1, X2, ..., Xn , ... une suite infinie de variables aléatoires indépendantes et Sn = X1 + ... + Xn la somme des n premières. Il suffit que Sn converge en loi vers une variable S pour que Sn converge presque sûrement (et par conséquent aussi en probabilité) vers S. Paul Levy a établi ce résultat pour des variables unidimensionnelles et J. Geffroy l’a généralisé à Rn . Kolmogorov a dégagé une condition de convergence des séries de variables indépendantes connue sous le nom de théorème des trois séries : Pour que Xn converge (en loi, en probabilité, ou presque sûrement, puisque nous venons de voir que les trois modes sont équivalents), il est nécessaire et suffisant qu’il existe M 礪 0 tel que, si l’on pose X n = Xn si | Xn | 諒 M et 0 si | Xn | 礪 M, les trois séries:
tend vers sa limite.On doit à Paul Levy un beau théorème sur la convergence des séries aléatoires, qu’il a établi en utilisant la fonction de concentration qui lui est due (cf. chap. 3). Soit X1, X2, ..., Xn , ... une suite infinie de variables aléatoires indépendantes et Sn = X1 + ... + Xn la somme des n premières. Il suffit que Sn converge en loi vers une variable S pour que Sn converge presque sûrement (et par conséquent aussi en probabilité) vers S. Paul Levy a établi ce résultat pour des variables unidimensionnelles et J. Geffroy l’a généralisé à Rn . Kolmogorov a dégagé une condition de convergence des séries de variables indépendantes connue sous le nom de théorème des trois séries : Pour que Xn converge (en loi, en probabilité, ou presque sûrement, puisque nous venons de voir que les trois modes sont équivalents), il est nécessaire et suffisant qu’il existe M 礪 0 tel que, si l’on pose X n = Xn si | Xn | 諒 M et 0 si | Xn | 礪 M, les trois séries: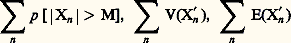 Dans cet énoncé s’introduit la notion de variable tronquée au niveau M. C’est un instrument de travail très utile en calcul des probabilités.On a également étudié le comportement des valeurs extrêmes d’un échantillon. Appelons mn et Mn respectivement la plus petite et la plus grande valeur d’un échantillon; on a les résultats suivants que l’on peut rapprocher des lois des grands nombres. Pour que Mn /n et mn /n convergent vers 0 en probabilité, il est nécessaire et suffisant que:
Dans cet énoncé s’introduit la notion de variable tronquée au niveau M. C’est un instrument de travail très utile en calcul des probabilités.On a également étudié le comportement des valeurs extrêmes d’un échantillon. Appelons mn et Mn respectivement la plus petite et la plus grande valeur d’un échantillon; on a les résultats suivants que l’on peut rapprocher des lois des grands nombres. Pour que Mn /n et mn /n convergent vers 0 en probabilité, il est nécessaire et suffisant que: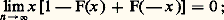 pour que Mn /n et mn /n convergent presque sûrement vers 0, il est nécessaire et suffisant que l’intégrale: soit convergente; pour que Mn /n et mn /n convergent presque complètement sûrement vers 0, il est nécessaire et suffisant que:
pour que Mn /n et mn /n convergent presque sûrement vers 0, il est nécessaire et suffisant que l’intégrale: soit convergente; pour que Mn /n et mn /n convergent presque complètement sûrement vers 0, il est nécessaire et suffisant que: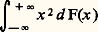 soit convergente.9. Certaines lois de probabilitésLois sur les histogrammesDans le chapitre précédent, nous avons introduit la notion d’histogramme de fréquence et nous avons vu qu’il y a une probabilité égale à 1 pour que la suite des Hn (x ) converge presque complètement sûrement vers F(x ). Quand F(x ) est continue, on peut donner sur cette convergence des précisions supplémentaires. On peut mesurer l’écart de Hn (x ) à F(x ) de bien des façons. Deux d’entre elles se prêtent très aisément aux calculs aboutissant à la loi de probabilité ou à la fonction caractéristique; on peut retenir les formules suivantes:
soit convergente.9. Certaines lois de probabilitésLois sur les histogrammesDans le chapitre précédent, nous avons introduit la notion d’histogramme de fréquence et nous avons vu qu’il y a une probabilité égale à 1 pour que la suite des Hn (x ) converge presque complètement sûrement vers F(x ). Quand F(x ) est continue, on peut donner sur cette convergence des précisions supplémentaires. On peut mesurer l’écart de Hn (x ) à F(x ) de bien des façons. Deux d’entre elles se prêtent très aisément aux calculs aboutissant à la loi de probabilité ou à la fonction caractéristique; on peut retenir les formules suivantes: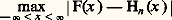 et:
et: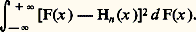
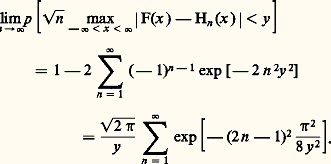 La loi de von Mises-Smirnov s’énonce ainsi: Si F(x ) est continue, la fonction caractéristique de la variable aléatoire:
La loi de von Mises-Smirnov s’énonce ainsi: Si F(x ) est continue, la fonction caractéristique de la variable aléatoire: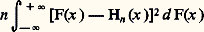 a pour limite:
a pour limite: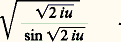 La deuxième égalité du théorème de Kolmogorov-Smirnov rattache de façon assez singulière la loi de répartition de la probabilité aux fonctions de Jacobi, sous-produit de la théorie des fonctions elliptiques [cf. ANALYSE MATHÉMATIQUE]. Si on considère le carré de la variable aléatoire de Kolmogorov-Smirnov, soit:
La deuxième égalité du théorème de Kolmogorov-Smirnov rattache de façon assez singulière la loi de répartition de la probabilité aux fonctions de Jacobi, sous-produit de la théorie des fonctions elliptiques [cf. ANALYSE MATHÉMATIQUE]. Si on considère le carré de la variable aléatoire de Kolmogorov-Smirnov, soit: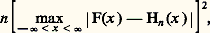 on peut établir que sa fonction caractéristique limite est:
on peut établir que sa fonction caractéristique limite est: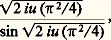 ce qui entraîne que cette nouvelle variable est, à la limite, la somme de deux variables indépendantes obéissant à une loi de von Mises-Smirnov à un changement d’échelle près. Ce fait n’a pas reçu jusqu’à présent d’explication.On a cherché à étendre ces théorèmes à plusieurs dimensions. Le théorème de Kolmogorov-Smirnov n’a pas reçu d’extension: on ignore la forme de la loi de l’écart maximum entre l’histogramme des fréquences et la fonction de répartition dans Rn , pour n 礪 1. Par contre, D. Dugué a pu donner la forme de la fonction caractéristique de la variable généralisant celle de von Mises-Smirnov. Appelons 淋p (u ) le produit infini:
ce qui entraîne que cette nouvelle variable est, à la limite, la somme de deux variables indépendantes obéissant à une loi de von Mises-Smirnov à un changement d’échelle près. Ce fait n’a pas reçu jusqu’à présent d’explication.On a cherché à étendre ces théorèmes à plusieurs dimensions. Le théorème de Kolmogorov-Smirnov n’a pas reçu d’extension: on ignore la forme de la loi de l’écart maximum entre l’histogramme des fréquences et la fonction de répartition dans Rn , pour n 礪 1. Par contre, D. Dugué a pu donner la forme de la fonction caractéristique de la variable généralisant celle de von Mises-Smirnov. Appelons 淋p (u ) le produit infini: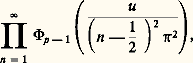 avec:
avec: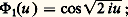 la fonction caractéristique cherchée sera:
la fonction caractéristique cherchée sera: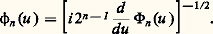 On a dressé des tables de toutes ces lois. Elles présentent cette particularité d’être indépendantes de la loi F dont on construit l’histogramme.Considérons maintenant n variables de Bernoulli X1, X2, ..., Xn indépendantes, pour lesquelles p = q = 1/2, les deux valeurs équiprobables prises par la variable étant + 1 et 漣 1, et soit Si = X1 + ... + Xi . Ces sommes permettent de définir un nombre aléatoire K, nombre de sommes positives ou nulles. La limite de la loi de probabilité de K/n a une forme particulièrement simple: elle est égale à:
On a dressé des tables de toutes ces lois. Elles présentent cette particularité d’être indépendantes de la loi F dont on construit l’histogramme.Considérons maintenant n variables de Bernoulli X1, X2, ..., Xn indépendantes, pour lesquelles p = q = 1/2, les deux valeurs équiprobables prises par la variable étant + 1 et 漣 1, et soit Si = X1 + ... + Xi . Ces sommes permettent de définir un nombre aléatoire K, nombre de sommes positives ou nulles. La limite de la loi de probabilité de K/n a une forme particulièrement simple: elle est égale à: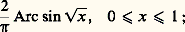 c’est la loi d’Arc sinus due à Paul Levy.On a un résultat encore plus simple dû à B. V. Gnedenko. Revenons à l’histogramme Hn (x ) d’un échantillon dont chaque variable obéit à la loi continue F(x ) et considérons l’ensemble des x pour lesquels on a Hn (x ) 礪 F(x ); cet ensemble aura une probabilité 刺n qui est un nombre aléatoire compris entre 0 et 1. Le théorème de Gnedenko énonce que:
c’est la loi d’Arc sinus due à Paul Levy.On a un résultat encore plus simple dû à B. V. Gnedenko. Revenons à l’histogramme Hn (x ) d’un échantillon dont chaque variable obéit à la loi continue F(x ) et considérons l’ensemble des x pour lesquels on a Hn (x ) 礪 F(x ); cet ensemble aura une probabilité 刺n qui est un nombre aléatoire compris entre 0 et 1. Le théorème de Gnedenko énonce que: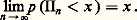 Lois dérivées de la loi de Laplace-GaussCet ensemble de lois de répartition est particulièrement utile dans la partie de la statistique appelée l’analyse de variance [cf. STATISTIQUE]. La loi de probabilité du carré d’une loi de Laplace-Gauss a pour fonction caractéristique:
Lois dérivées de la loi de Laplace-GaussCet ensemble de lois de répartition est particulièrement utile dans la partie de la statistique appelée l’analyse de variance [cf. STATISTIQUE]. La loi de probabilité du carré d’une loi de Laplace-Gauss a pour fonction caractéristique: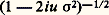 si la variable est centrée (valeur moyenne nulle), 靖2 étant la variance. La fonction caractéristique de la somme des carrés de n variables de Laplace-Gauss ayant même loi de probabilité est donc:
si la variable est centrée (valeur moyenne nulle), 靖2 étant la variance. La fonction caractéristique de la somme des carrés de n variables de Laplace-Gauss ayant même loi de probabilité est donc: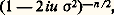 et sa loi de probabilité est:
et sa loi de probabilité est: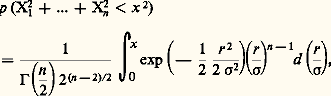 où l’on désigne par 臨 la fonction gamma d’Euler (cf. fonction GAMMA). En tenant compte des notations adoptées au moment où cette loi a été tabulée par Kark Pearson, on l’appelle parfois la loi du 﨑2, ou loi 臨 incomplète.La loi de probabilité du quotient de deux sommes de carrés de variables aléatoires de Laplace-Gauss de valeur moyenne nulle et de même variance, toutes ces variables étant indépendantes, constitue ce que l’on nomme la loi de Behrens-Fisher (ou loi de Snedecor , à un changement de variable près).On a avec ces hypothèses:
où l’on désigne par 臨 la fonction gamma d’Euler (cf. fonction GAMMA). En tenant compte des notations adoptées au moment où cette loi a été tabulée par Kark Pearson, on l’appelle parfois la loi du 﨑2, ou loi 臨 incomplète.La loi de probabilité du quotient de deux sommes de carrés de variables aléatoires de Laplace-Gauss de valeur moyenne nulle et de même variance, toutes ces variables étant indépendantes, constitue ce que l’on nomme la loi de Behrens-Fisher (ou loi de Snedecor , à un changement de variable près).On a avec ces hypothèses: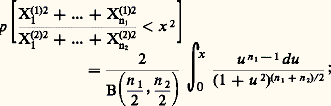 ce quotient porte parfois le nom de z de Fisher et la loi est dite B-incomplète, B étant la fonction eulérienne:
ce quotient porte parfois le nom de z de Fisher et la loi est dite B-incomplète, B étant la fonction eulérienne: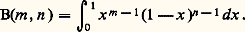 Dans le même ordre d’idée, la loi de Student est la loi du quotient d’une variable de Laplace-Gauss par la racine carrée de la somme des carrés de n variables de Laplace-Gauss indépendantes entre elles et indépendantes de la première variable. Si on appelle T cette variable, on a:
Dans le même ordre d’idée, la loi de Student est la loi du quotient d’une variable de Laplace-Gauss par la racine carrée de la somme des carrés de n variables de Laplace-Gauss indépendantes entre elles et indépendantes de la première variable. Si on appelle T cette variable, on a: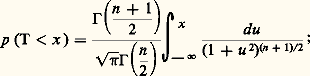 cette loi a été dégagée par le probabiliste W. S. Gosset à qui la firme qui l’employait imposait de signer ses travaux du pseudonyme de Student: la présence, alors, d’un statisticien dans l’état-major de direction d’une entreprise industrielle constituait un secret de fabrication!10. Chaînes de Markov et martingalesOn appelle chaîne une suite de variables aléatoires X1, X2, ..., Xn , ... telles que la loi de probabilité de Xn dépende des épreuves précédentes. Une chaîne de Markov simple est une suite de telles variables dans laquelle la loi de Xn dépend uniquement de l’épreuve Xn size=1漣1. Supposons que 行 soit l’ensemble1, 2, ..., n des n premiers entiers. Appelons pij la probabilité pour Xn de l’événement j , l’épreuve précédente de rang n 漣 1 étant i ; naturellement, on a:
cette loi a été dégagée par le probabiliste W. S. Gosset à qui la firme qui l’employait imposait de signer ses travaux du pseudonyme de Student: la présence, alors, d’un statisticien dans l’état-major de direction d’une entreprise industrielle constituait un secret de fabrication!10. Chaînes de Markov et martingalesOn appelle chaîne une suite de variables aléatoires X1, X2, ..., Xn , ... telles que la loi de probabilité de Xn dépende des épreuves précédentes. Une chaîne de Markov simple est une suite de telles variables dans laquelle la loi de Xn dépend uniquement de l’épreuve Xn size=1漣1. Supposons que 行 soit l’ensemble1, 2, ..., n des n premiers entiers. Appelons pij la probabilité pour Xn de l’événement j , l’épreuve précédente de rang n 漣 1 étant i ; naturellement, on a: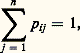 quel que soit i . Considérons la matrice:
quel que soit i . Considérons la matrice: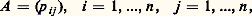 que l’on appelle souvent une matrice stochastique . La matrice unité est une matrice stochastique et le produit AB de deux matrices stochastiques est une matrice stochastique: en effet, les éléments de AB sont bien entendu positifs et, de plus, on a:
que l’on appelle souvent une matrice stochastique . La matrice unité est une matrice stochastique et le produit AB de deux matrices stochastiques est une matrice stochastique: en effet, les éléments de AB sont bien entendu positifs et, de plus, on a: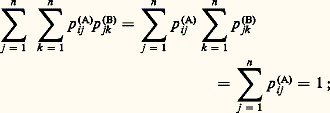 l’ensemble des matrices stochastiques forme donc un semi-groupe. En particulier, les puissances d’une même matrice A forment un semi-groupe; étant donné les axiomes du calcul des probabilités, la matrice An a pour élément de la i -ième ligne et de la j -ième colonne la probabilité pour la n -ième variable Xn de l’événement j , la première épreuve étant i et les probabilités de passage étant les mêmes quel que soit l’indice n (on dit que la chaîne est stable). Cherchons le comportement de An quand n augmente indéfiniment. La matrice A a pour valeur propre l’unité, car l’ensemble des équations:
l’ensemble des matrices stochastiques forme donc un semi-groupe. En particulier, les puissances d’une même matrice A forment un semi-groupe; étant donné les axiomes du calcul des probabilités, la matrice An a pour élément de la i -ième ligne et de la j -ième colonne la probabilité pour la n -ième variable Xn de l’événement j , la première épreuve étant i et les probabilités de passage étant les mêmes quel que soit l’indice n (on dit que la chaîne est stable). Cherchons le comportement de An quand n augmente indéfiniment. La matrice A a pour valeur propre l’unité, car l’ensemble des équations: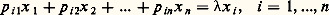 est évidemment satisfait si tous les xi sont égaux et si = 1. On a, d’autre part, l’inégalité:
est évidemment satisfait si tous les xi sont égaux et si = 1. On a, d’autre part, l’inégalité: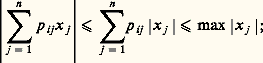 si on a à la fois pij 0, quels que soient i , j , et la non-réalisation de l’ensemble des égalités x 1 = x 2 = ... = xn , la seconde inégalité est stricte. Si on prend i égal à l’indice j 1 tel que max | xj | = | x j 1 | , on a:
si on a à la fois pij 0, quels que soient i , j , et la non-réalisation de l’ensemble des égalités x 1 = x 2 = ... = xn , la seconde inégalité est stricte. Si on prend i égal à l’indice j 1 tel que max | xj | = | x j 1 | , on a: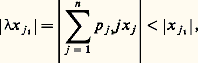 ce qui indique que les modules des valeurs propres différentes de 1 sont strictement inférieurs à 1. On montre que, dans le cas où tous les pij sont différents de 0, la valeur propre = 1 est simple. Il en résulte que, si l’on donne à A sa forme réduite R (diagonale, ou réduite de Cauchy si les valeurs propres différentes de 1 sont multiples), avec A = TRT size=1漣1, on aura Am = TRmT size=1漣1 et, la valeur propre = 1 étant simple et les autres valeurs propres étant de modules inférieurs à 1, la matrice Rm tendra vers une matrice dont le seul élément différent de 0 sera celui de la première ligne, première colonne; cet élément est égal à 1. La matrice RmT size=1漣1 tendra vers une matrice dont les seuls éléments non nuls sont ceux de la première ligne, égaux à 見1, 見2, ..., 見n , et la matrice Am tendra vers (ti1 見j ) si tij est l’élément général de T ; comme Am est une matrice stochastique, on a:
ce qui indique que les modules des valeurs propres différentes de 1 sont strictement inférieurs à 1. On montre que, dans le cas où tous les pij sont différents de 0, la valeur propre = 1 est simple. Il en résulte que, si l’on donne à A sa forme réduite R (diagonale, ou réduite de Cauchy si les valeurs propres différentes de 1 sont multiples), avec A = TRT size=1漣1, on aura Am = TRmT size=1漣1 et, la valeur propre = 1 étant simple et les autres valeurs propres étant de modules inférieurs à 1, la matrice Rm tendra vers une matrice dont le seul élément différent de 0 sera celui de la première ligne, première colonne; cet élément est égal à 1. La matrice RmT size=1漣1 tendra vers une matrice dont les seuls éléments non nuls sont ceux de la première ligne, égaux à 見1, 見2, ..., 見n , et la matrice Am tendra vers (ti1 見j ) si tij est l’élément général de T ; comme Am est une matrice stochastique, on a: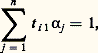 quel que soit i , et par suite:
quel que soit i , et par suite: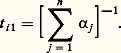 Il en résulte que le nombre:
Il en résulte que le nombre: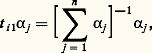 qui est, quand m tend vers l’infini, la limite de la probabilité pour que le système passe de l’état i à l’état j en m épreuves, est indépendant de i , c’est-à-dire de l’état initial. On a donc un premier cas d’ergodicité (indépendance de l’état initial) quand tous les pij sont différents de 0.Afin d’illustrer cette étude, Poincaré a pris l’exemple du battage des cartes: Soit un jeu de N cartes; la probabilité pour qu’une carte donnée occupe une place déterminée après un très grand nombre de battages est indépendante de la place que cette carte occupait initialement; compte tenu de la symétrie du problème, cette probabilité est 1/N et elle ne dépend pas non plus, dans ce cas , de la place finale.On appelle martingale une suite de variables aléatoires X1, X2, ..., Xn ,... telles que:
qui est, quand m tend vers l’infini, la limite de la probabilité pour que le système passe de l’état i à l’état j en m épreuves, est indépendant de i , c’est-à-dire de l’état initial. On a donc un premier cas d’ergodicité (indépendance de l’état initial) quand tous les pij sont différents de 0.Afin d’illustrer cette étude, Poincaré a pris l’exemple du battage des cartes: Soit un jeu de N cartes; la probabilité pour qu’une carte donnée occupe une place déterminée après un très grand nombre de battages est indépendante de la place que cette carte occupait initialement; compte tenu de la symétrie du problème, cette probabilité est 1/N et elle ne dépend pas non plus, dans ce cas , de la place finale.On appelle martingale une suite de variables aléatoires X1, X2, ..., Xn ,... telles que: ces suites discrètes de variables aléatoires ont été généralisées sous forme de processus continus (cf. processus STOCHASTIQUES).11. Quelques problèmes simplesProblème de l’aiguille de BuffonDans le volume VII du Supplément à son Histoire naturelle , Buffon aborde assez curieusement de nombreux problèmes de calcul des probabilités et de statistique (en particulier, il est parmi les premiers à avoir dressé des tables de mortalité). L’un des plus célèbres est celui de l’aiguille, dont l’énoncé est le suivant: Sur un plan sont tracées des droites parallèles distantes de h . On jette «au hasard» sur ce plan une aiguille de longueur l , avec l 麗 h ; quelle est la probabilité pour que cette aiguille rencontre l’une des droites?Il convient de préciser ce que l’on entend par «au hasard» dans un tel problème, comme d’ailleurs dans bien d’autres, ainsi que nous le verrons plus loin. «Au hasard» veut dire ici que la probabilité pour que le milieu de l’aiguille tombe dans une région donnée est proportionnelle à l’aire de cette région et que l’orientation de l’aiguille, qui est indépendante de la position du milieu, obéit aussi à une loi uniforme: la probabilité pour que l’intersection de l’aiguille orientée avec une circonférence de rayon 1 se trouve sur un certain arc est égale à la mesure de cet arc divisé par 2 神.Une solution élégante de ce problème a été donnée par E. Barbier vers 1860. Appelons N la variable aléatoire égale au nombre de points de rencontre de l’aiguille et du réseau de droites parallèles; N prend la valeur 0 avec la probabilité 1 漣 p et la valeur 1 avec la probabilité p que l’on cherche: E(N) = p . Considérons maintenant une ligne polygonale, fermée ou non, de n côtés, et appelons Ni la variable aléatoire définie comme précédemment relative à chaque côté. Les différentes variables Ni ne sont pas indépendantes, mais on sait que, même dans ce cas (cf. chap. 3), on a:
ces suites discrètes de variables aléatoires ont été généralisées sous forme de processus continus (cf. processus STOCHASTIQUES).11. Quelques problèmes simplesProblème de l’aiguille de BuffonDans le volume VII du Supplément à son Histoire naturelle , Buffon aborde assez curieusement de nombreux problèmes de calcul des probabilités et de statistique (en particulier, il est parmi les premiers à avoir dressé des tables de mortalité). L’un des plus célèbres est celui de l’aiguille, dont l’énoncé est le suivant: Sur un plan sont tracées des droites parallèles distantes de h . On jette «au hasard» sur ce plan une aiguille de longueur l , avec l 麗 h ; quelle est la probabilité pour que cette aiguille rencontre l’une des droites?Il convient de préciser ce que l’on entend par «au hasard» dans un tel problème, comme d’ailleurs dans bien d’autres, ainsi que nous le verrons plus loin. «Au hasard» veut dire ici que la probabilité pour que le milieu de l’aiguille tombe dans une région donnée est proportionnelle à l’aire de cette région et que l’orientation de l’aiguille, qui est indépendante de la position du milieu, obéit aussi à une loi uniforme: la probabilité pour que l’intersection de l’aiguille orientée avec une circonférence de rayon 1 se trouve sur un certain arc est égale à la mesure de cet arc divisé par 2 神.Une solution élégante de ce problème a été donnée par E. Barbier vers 1860. Appelons N la variable aléatoire égale au nombre de points de rencontre de l’aiguille et du réseau de droites parallèles; N prend la valeur 0 avec la probabilité 1 漣 p et la valeur 1 avec la probabilité p que l’on cherche: E(N) = p . Considérons maintenant une ligne polygonale, fermée ou non, de n côtés, et appelons Ni la variable aléatoire définie comme précédemment relative à chaque côté. Les différentes variables Ni ne sont pas indépendantes, mais on sait que, même dans ce cas (cf. chap. 3), on a: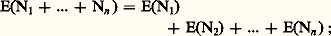 en passant à la limite, cela revient à dire que, quelle que soit la forme d’une courbe, l’espérance mathématique du nombre de points d’intersection de cette courbe avec le réseau de droites parallèles est proportionnelle à la longueur L de cette courbe, donc de la forme k L. Si on prend pour courbe un cercle de diamètre h , le nombre de points d’intersection avec le réseau est égal à 2 avec une probabilité égale à 1; l’espérance mathématique dans ce cas est donc 2 et, par suite, k 神h = 2, donc k = 2/ 神h . Ainsi, la probabilité d’une intersection de l’aiguille et du réseau est égale, si l 麗 h , à 2 l / 神h . Si l = h/ 2, cette probabilité est donc égale à 1/ 神. D’après ce que l’on a vu dans le chapitre 8, la fréquence d’un tel résultat est une estimation de la probabilité. Sur ce cas très précis, des expériences sont continuellement faites au palais de la Découverte à Paris.Probabilités en arithmétiqueDeux nombres entiers positifs étant choisis «au hasard», quelle est la probabilité pour qu’ils soient premiers entre eux? Ici encore, il faut préciser l’expression «au hasard»; elle voudrait signifier «en donnant la même probabilité à chaque entier positif», mais il n’est pas possible de donner directement cette égalité de chances: si elle était nulle, la probabilité de l’ensemble des entiers serait nulle, et si elle était différente de 0, la probabilité de l’ensemble des entiers serait infinie. Il faut donc entendre «au hasard» de la façon suivante: on considère tous les entiers inférieurs à N; en attribuant la même probabilité à chacun de ces entiers, on calculera la probabilité pour que deux entiers indépendants soient premiers entre eux et on calculera la limite de cette probabilité lorsque N augmente indéfiniment. Étant entendue de cette manière, la probabilité pour qu’un nombre soit multiple de n est égale à 1/n . Appelons p la probabilité pour que deux nombres soient premiers entre eux et pn la probabilité pour que leur plus grand commun diviseur soit n . On aura naturellement:
en passant à la limite, cela revient à dire que, quelle que soit la forme d’une courbe, l’espérance mathématique du nombre de points d’intersection de cette courbe avec le réseau de droites parallèles est proportionnelle à la longueur L de cette courbe, donc de la forme k L. Si on prend pour courbe un cercle de diamètre h , le nombre de points d’intersection avec le réseau est égal à 2 avec une probabilité égale à 1; l’espérance mathématique dans ce cas est donc 2 et, par suite, k 神h = 2, donc k = 2/ 神h . Ainsi, la probabilité d’une intersection de l’aiguille et du réseau est égale, si l 麗 h , à 2 l / 神h . Si l = h/ 2, cette probabilité est donc égale à 1/ 神. D’après ce que l’on a vu dans le chapitre 8, la fréquence d’un tel résultat est une estimation de la probabilité. Sur ce cas très précis, des expériences sont continuellement faites au palais de la Découverte à Paris.Probabilités en arithmétiqueDeux nombres entiers positifs étant choisis «au hasard», quelle est la probabilité pour qu’ils soient premiers entre eux? Ici encore, il faut préciser l’expression «au hasard»; elle voudrait signifier «en donnant la même probabilité à chaque entier positif», mais il n’est pas possible de donner directement cette égalité de chances: si elle était nulle, la probabilité de l’ensemble des entiers serait nulle, et si elle était différente de 0, la probabilité de l’ensemble des entiers serait infinie. Il faut donc entendre «au hasard» de la façon suivante: on considère tous les entiers inférieurs à N; en attribuant la même probabilité à chacun de ces entiers, on calculera la probabilité pour que deux entiers indépendants soient premiers entre eux et on calculera la limite de cette probabilité lorsque N augmente indéfiniment. Étant entendue de cette manière, la probabilité pour qu’un nombre soit multiple de n est égale à 1/n . Appelons p la probabilité pour que deux nombres soient premiers entre eux et pn la probabilité pour que leur plus grand commun diviseur soit n . On aura naturellement: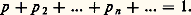 D’autre part, pour que n soit le plus grand commun diviseur de deux nombres, il faut et il suffit que chacun de ces deux nombres soit multiple de n et que les quotients de ces deux nombres par n soient premiers entre eux; on a donc pn = p/n 2. Par conséquent:
D’autre part, pour que n soit le plus grand commun diviseur de deux nombres, il faut et il suffit que chacun de ces deux nombres soit multiple de n et que les quotients de ces deux nombres par n soient premiers entre eux; on a donc pn = p/n 2. Par conséquent: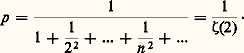 On établit de la même façon que la probabilité pour que k nombres choisis au hasard soient premiers entre eux est 1/ 﨣(k ). Ce problème est donc étroitement lié à la fonction 﨣(s ) de Riemann (cf. fonction ZÊTA). On sait que:
On établit de la même façon que la probabilité pour que k nombres choisis au hasard soient premiers entre eux est 1/ 﨣(k ). Ce problème est donc étroitement lié à la fonction 﨣(s ) de Riemann (cf. fonction ZÊTA). On sait que: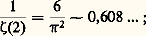 la probabilité pour que quatre nombres pris au hasard soient premiers entre eux est égale à:
la probabilité pour que quatre nombres pris au hasard soient premiers entre eux est égale à: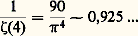 Promenade au hasardConsidérons un quadrillage du plan et déterminons un parcours sur ce quadrillage en tirant au sort la direction prise à chaque sommet, chacune des quatre directions ayant une chance égale. On a ainsi une image du mouvement brownien à deux dimensions. Soit P(x , y ) la probabilité pour que le chemin passe par un point du quadrillage de coordonnées (x , y ). On a donc:
Promenade au hasardConsidérons un quadrillage du plan et déterminons un parcours sur ce quadrillage en tirant au sort la direction prise à chaque sommet, chacune des quatre directions ayant une chance égale. On a ainsi une image du mouvement brownien à deux dimensions. Soit P(x , y ) la probabilité pour que le chemin passe par un point du quadrillage de coordonnées (x , y ). On a donc: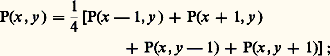 si on fait tendre le côté du quadrillage vers 0, on voit que la fonction P(x , y ) satisfait à l’équation de Laplace:
si on fait tendre le côté du quadrillage vers 0, on voit que la fonction P(x , y ) satisfait à l’équation de Laplace: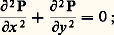 c’est une fonction harmonique et cette démonstration «heuristique» établit le lien entre le calcul des probabilités et la théorie du potentiel.Considérons un contour fermé 臨, somme de deux arcs 塚1 et 塚2, et plaçons-nous en un point intérieur (x 0, y 0). Quelle est la probabilité pour qu’un parcours au hasard, déterminé comme ci-dessus, franchisse la frontière 臨 sur l’arc 塚1? D’après ce que nous venons de voir, cette probabilité devra être la valeur d’une fonction harmonique à l’intérieur de 臨 et prendra la valeur 1 sur 塚1 et la valeur 0 sur 塚2. On est donc ramené à résoudre un problème de Dirichlet particulier. La valeur P(x 0, y 0) est ce que l’on nomme en théorie des fonctions la mesure de Nevanlinna de l’arc 塚1 sur le contour 臨 et relative au point (x 0, y 0).Dans des cas particuliers où 臨 a une forme simple, on obtient facilement l’expression de P(x 0, y 0). Supposons que 臨 soit la courbe fermée réunion de deux arcs de cercle se coupant en M1 et M2 (fig. 3); si on désigne par z 1 et z 2 les affixes de M1 et M2, la fonction de z :
c’est une fonction harmonique et cette démonstration «heuristique» établit le lien entre le calcul des probabilités et la théorie du potentiel.Considérons un contour fermé 臨, somme de deux arcs 塚1 et 塚2, et plaçons-nous en un point intérieur (x 0, y 0). Quelle est la probabilité pour qu’un parcours au hasard, déterminé comme ci-dessus, franchisse la frontière 臨 sur l’arc 塚1? D’après ce que nous venons de voir, cette probabilité devra être la valeur d’une fonction harmonique à l’intérieur de 臨 et prendra la valeur 1 sur 塚1 et la valeur 0 sur 塚2. On est donc ramené à résoudre un problème de Dirichlet particulier. La valeur P(x 0, y 0) est ce que l’on nomme en théorie des fonctions la mesure de Nevanlinna de l’arc 塚1 sur le contour 臨 et relative au point (x 0, y 0).Dans des cas particuliers où 臨 a une forme simple, on obtient facilement l’expression de P(x 0, y 0). Supposons que 臨 soit la courbe fermée réunion de deux arcs de cercle se coupant en M1 et M2 (fig. 3); si on désigne par z 1 et z 2 les affixes de M1 et M2, la fonction de z :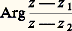 est une fonction harmonique. Si 猪1 est l’affixe d’un point de 塚1 et 猪2 l’affixe d’un point de 塚2, la fonction:
est une fonction harmonique. Si 猪1 est l’affixe d’un point de 塚1 et 猪2 l’affixe d’un point de 塚2, la fonction: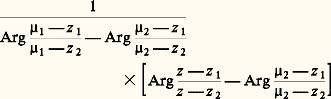 est une fonction harmonique prenant la valeur 1 sur 塚1 et la valeur 0 sur 塚2. C’est donc la probabilité cherchée: c’est la fonction linéaire de l’«angle sous lequel on voit le segment M1M2 du point M», fonction nulle sur 塚2 et égale à 1 sur 塚1.Si le domaine dans lequel se trouve M est limité par deux cercles non sécants, 塚1 étant l’un des cercles et 塚2 l’autre, désignons par 1 et 2 les points limites du faisceau linéaire déterminé par ces deux cercles et soit z 1 et z 2 les affixes de ces points. La fonction | z 漣 z 1 | / | z 漣 z 2 | est harmonique et on a ici pour expression de la probabilité de sortie sur 塚1:
est une fonction harmonique prenant la valeur 1 sur 塚1 et la valeur 0 sur 塚2. C’est donc la probabilité cherchée: c’est la fonction linéaire de l’«angle sous lequel on voit le segment M1M2 du point M», fonction nulle sur 塚2 et égale à 1 sur 塚1.Si le domaine dans lequel se trouve M est limité par deux cercles non sécants, 塚1 étant l’un des cercles et 塚2 l’autre, désignons par 1 et 2 les points limites du faisceau linéaire déterminé par ces deux cercles et soit z 1 et z 2 les affixes de ces points. La fonction | z 漣 z 1 | / | z 漣 z 2 | est harmonique et on a ici pour expression de la probabilité de sortie sur 塚1: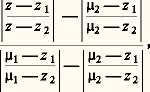 en désignant par 猪1 l’affixe d’un point de 塚1 et par 猪2 l’affixe d’un point de 塚2.Ce lien entre la théorie du potentiel et le calcul des probabilités est à la base de certaines méthodes dites de Monte-Carlo qui permettent la solution approchée du problème de Dirichlet. Étant donné un quadrillage, il est facile de simuler une promenade au hasard au moyen de contacts électriques déclenchés aléatoirement. On peut donc dénombrer, et par suite évaluer, la fréquence des parcours issus de M et sortant de 臨 sur 塚1 (fig. 4). D’après ce que nous venons de voir, c’est la valeur en M d’une fonction harmonique prenant la valeur 1 sur 塚1 et la valeur 0 sur 塚2; ou, plus exactemnt, c’est l’estimation de cette valeur, d’autant plus précise aléatoirement que le nombre d’expériences sera plus grand. Une fonction continue sur 臨 peut être approchée par palier, c’est-à-dire par des combinaisons linéaires de fonctions égales à 1 sur des arcs tels que 塚1 et à 0 sur les arcs 塚2. La valeur de la fonction harmonique en M sera donc approchée par les mêmes combinaisons linéaires des fréquences correspondantes de sortie. Ces méthodes sont très couramment utilisées.Méthodes des fonctions arbitrairesFréchet, dans Recherches modernes sur le calcul des probabilités , écrit: «Il arrive que la répartition de la probabilité dépende d’un paramètre n de manière que, lorsque le paramètre augmente indéfiniment, la répartition correspondante tende à se régulariser. Si le paramètre n définit le nombre d’éléments d’un réseau géométrique qui devient de plus en plus serré quand n croît, on constate que, si l’on part d’une répartition arbitraire des probabilités, cette répartition tend vers une limite indépendante de la répartition initiale. C’est l’idée qui est à la base de la méthode des fonctions arbitraires imaginée par Henri Poincaré.» Fréchet ajoute qu’il s’agit d’une des contributions les plus importantes au progrès moderne du calcul des probabilités.Cette méthode est à rapprocher de la «loi des grands nombres» (cf. chap. 8). La roulette en est un bon exemple d’application. Soit un cercle de rayon 1, mobile autour de son centre et divisé en 2n arcs alternativement rouges et noirs et de même longueur 神/n . Soit la variable aléatoire constituée par l’angle de rotation du cercle. Supposons que:
en désignant par 猪1 l’affixe d’un point de 塚1 et par 猪2 l’affixe d’un point de 塚2.Ce lien entre la théorie du potentiel et le calcul des probabilités est à la base de certaines méthodes dites de Monte-Carlo qui permettent la solution approchée du problème de Dirichlet. Étant donné un quadrillage, il est facile de simuler une promenade au hasard au moyen de contacts électriques déclenchés aléatoirement. On peut donc dénombrer, et par suite évaluer, la fréquence des parcours issus de M et sortant de 臨 sur 塚1 (fig. 4). D’après ce que nous venons de voir, c’est la valeur en M d’une fonction harmonique prenant la valeur 1 sur 塚1 et la valeur 0 sur 塚2; ou, plus exactemnt, c’est l’estimation de cette valeur, d’autant plus précise aléatoirement que le nombre d’expériences sera plus grand. Une fonction continue sur 臨 peut être approchée par palier, c’est-à-dire par des combinaisons linéaires de fonctions égales à 1 sur des arcs tels que 塚1 et à 0 sur les arcs 塚2. La valeur de la fonction harmonique en M sera donc approchée par les mêmes combinaisons linéaires des fréquences correspondantes de sortie. Ces méthodes sont très couramment utilisées.Méthodes des fonctions arbitrairesFréchet, dans Recherches modernes sur le calcul des probabilités , écrit: «Il arrive que la répartition de la probabilité dépende d’un paramètre n de manière que, lorsque le paramètre augmente indéfiniment, la répartition correspondante tende à se régulariser. Si le paramètre n définit le nombre d’éléments d’un réseau géométrique qui devient de plus en plus serré quand n croît, on constate que, si l’on part d’une répartition arbitraire des probabilités, cette répartition tend vers une limite indépendante de la répartition initiale. C’est l’idée qui est à la base de la méthode des fonctions arbitraires imaginée par Henri Poincaré.» Fréchet ajoute qu’il s’agit d’une des contributions les plus importantes au progrès moderne du calcul des probabilités.Cette méthode est à rapprocher de la «loi des grands nombres» (cf. chap. 8). La roulette en est un bon exemple d’application. Soit un cercle de rayon 1, mobile autour de son centre et divisé en 2n arcs alternativement rouges et noirs et de même longueur 神/n . Soit la variable aléatoire constituée par l’angle de rotation du cercle. Supposons que: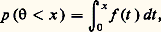 c’est-à-dire que la loi de probabilité de soit absolument continue. La probabilité pour que, au cours de sa rotation, le cercle s’arrête devant un repère fixe sur un arc noir sera égale à:
c’est-à-dire que la loi de probabilité de soit absolument continue. La probabilité pour que, au cours de sa rotation, le cercle s’arrête devant un repère fixe sur un arc noir sera égale à: l’intégrale étant étendue à tous les arcs noirs; de même, la probabilité d’arrêt sur un arc rouge est:
l’intégrale étant étendue à tous les arcs noirs; de même, la probabilité d’arrêt sur un arc rouge est: l’intégrale étant étendue aux arcs rouges. Naturellement, la somme de ces deux intégrales est égale à 1. Henri Poincaré a établi que ces deux intégrales tendaient vers une même limite, et par conséquent vers 1/2, quelle que soit f , à condition toutefois que f soit dérivable. É. Borel a étendu ce résultat à toutes les fonctions f continues et M. Fréchet l’a démontré dans le cas où f est bornée et intégrable au sens de Riemann.Problèmes de scrutinOn donne le nom de problème de scrutin à un ensemble de questions qui relient le calcul des probabilités à l’analyse combinatoire (cf. analyse COMBINATOIRE). Le plus simple de ces problèmes est le suivant: Une urne contient 2n bulletins, n au nom de A et n au nom de B. On dépouille le scrutin (bien entendu, à chaque opération les bulletins restants ont une probabilité égale d’être extraits). Quelle est la probabilité pour que, au cours du dépouillement, le nombre de bulletins sortis de l’urne au nom de A reste supérieur (strictement ou non) au nombre de bulletins sortis au nom de B? Un dépouillement peut être représenté (fig. 5) par un cheminement sur le quadrillage d’un carré dont chaque côté est divisé en n segments; un bulletin au nom de A sera représenté par un trait horizontal et un bulletin au nom de B par un trait vertical. Il y a évidemment bijection entre l’ensemble des dépouillements et l’ensemble des parcours joignant O à P et comprenant des segments parcourus de gauche à droite ou de bas en haut; il y a donc en tout:
l’intégrale étant étendue aux arcs rouges. Naturellement, la somme de ces deux intégrales est égale à 1. Henri Poincaré a établi que ces deux intégrales tendaient vers une même limite, et par conséquent vers 1/2, quelle que soit f , à condition toutefois que f soit dérivable. É. Borel a étendu ce résultat à toutes les fonctions f continues et M. Fréchet l’a démontré dans le cas où f est bornée et intégrable au sens de Riemann.Problèmes de scrutinOn donne le nom de problème de scrutin à un ensemble de questions qui relient le calcul des probabilités à l’analyse combinatoire (cf. analyse COMBINATOIRE). Le plus simple de ces problèmes est le suivant: Une urne contient 2n bulletins, n au nom de A et n au nom de B. On dépouille le scrutin (bien entendu, à chaque opération les bulletins restants ont une probabilité égale d’être extraits). Quelle est la probabilité pour que, au cours du dépouillement, le nombre de bulletins sortis de l’urne au nom de A reste supérieur (strictement ou non) au nombre de bulletins sortis au nom de B? Un dépouillement peut être représenté (fig. 5) par un cheminement sur le quadrillage d’un carré dont chaque côté est divisé en n segments; un bulletin au nom de A sera représenté par un trait horizontal et un bulletin au nom de B par un trait vertical. Il y a évidemment bijection entre l’ensemble des dépouillements et l’ensemble des parcours joignant O à P et comprenant des segments parcourus de gauche à droite ou de bas en haut; il y a donc en tout: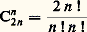 dépouillements possibles, tous étant également probables. Les dépouillements au cours desquels A aura toujours strictement la majorité (sauf naturellement au début et à la fin de l’opération, où les nombres de bulletins de A et de B seront égaux à 0 et à n respectivement) sont ceux qui sont associés aux chemins strictement en dessous de la diagonale (sauf aux extrémités); soit Bn leur nombre. On a:
dépouillements possibles, tous étant également probables. Les dépouillements au cours desquels A aura toujours strictement la majorité (sauf naturellement au début et à la fin de l’opération, où les nombres de bulletins de A et de B seront égaux à 0 et à n respectivement) sont ceux qui sont associés aux chemins strictement en dessous de la diagonale (sauf aux extrémités); soit Bn leur nombre. On a: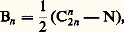 où N est le nombre de chemins traversant ou touchant au moins une fois la diagonale. Ce dernier ensemble est la réunion de quatre sous-ensembles sans élément commun: les chemins commençant par un trait horizontal et finissant par un trait horizontal; les chemins commençant par un trait horizontal et finissant par un trait vertical; les chemins commençant par un trait vertical et finissant par un trait vertical; les chemins commençant par un trait vertical et finissant par un trait horizontal. On montre facilement (principe de symétrie dû à D. André et à lord Kelvin) que deux quelconques de ces quatre ensembles peuvent être mis en bijection et par conséquent que ces quatre sous-ensembles ont le même nombre d’éléments; ce cardinal est égal à Cn size=1漣 12n size=1漣 2. Finalement, on a:
où N est le nombre de chemins traversant ou touchant au moins une fois la diagonale. Ce dernier ensemble est la réunion de quatre sous-ensembles sans élément commun: les chemins commençant par un trait horizontal et finissant par un trait horizontal; les chemins commençant par un trait horizontal et finissant par un trait vertical; les chemins commençant par un trait vertical et finissant par un trait vertical; les chemins commençant par un trait vertical et finissant par un trait horizontal. On montre facilement (principe de symétrie dû à D. André et à lord Kelvin) que deux quelconques de ces quatre ensembles peuvent être mis en bijection et par conséquent que ces quatre sous-ensembles ont le même nombre d’éléments; ce cardinal est égal à Cn size=1漣 12n size=1漣 2. Finalement, on a: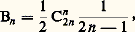 et la probabilité cherchée est donc:
et la probabilité cherchée est donc: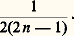 Si on appelle An le nombre de chemins au-dessous de la diagonale mais pouvant la toucher sans la traverser (en bijection avec les dépouillements où A conserve la majorité sans éventuellement l’avoir strictement), on voit que An size=1漣 1 = Bn ; la probabilité correspondante d’un dépouillement au cours duquel A conserve la majorité (éventuellement non stricte) est donc 1/(n + 1).La même méthode (D. André – lord Kelvin) permet de répondre à la question suivante: Quelle est la probabilité pour que, au cours d’un dépouillement, le nombre de bulletins au nom de A soit toujours strictement supérieur au nombre de bulletins B diminué de h ? Sur la figure 5, on a indiqué en pointillé la ligne que ne doivent pas franchir ou toucher les chemins représentatifs dans le cas où h = 2. Si on désigne par B n ,h le nombre de ces chemins, on a:
Si on appelle An le nombre de chemins au-dessous de la diagonale mais pouvant la toucher sans la traverser (en bijection avec les dépouillements où A conserve la majorité sans éventuellement l’avoir strictement), on voit que An size=1漣 1 = Bn ; la probabilité correspondante d’un dépouillement au cours duquel A conserve la majorité (éventuellement non stricte) est donc 1/(n + 1).La même méthode (D. André – lord Kelvin) permet de répondre à la question suivante: Quelle est la probabilité pour que, au cours d’un dépouillement, le nombre de bulletins au nom de A soit toujours strictement supérieur au nombre de bulletins B diminué de h ? Sur la figure 5, on a indiqué en pointillé la ligne que ne doivent pas franchir ou toucher les chemins représentatifs dans le cas où h = 2. Si on désigne par B n ,h le nombre de ces chemins, on a: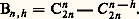 Toujours en utilisant la même méthode, on montre que, s’il y a n 1 bulletins A et n 2 bulletins B, avec n 1 礪 n 2, la probabilité pour que A ait toujours strictement la majorité est:
Toujours en utilisant la même méthode, on montre que, s’il y a n 1 bulletins A et n 2 bulletins B, avec n 1 礪 n 2, la probabilité pour que A ait toujours strictement la majorité est: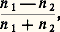 et la probabilité pour qu’il ait la majorité éventuellement non stricte est:
et la probabilité pour qu’il ait la majorité éventuellement non stricte est: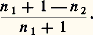 D’autres problèmes ont des solutions qui, à la limite, permettent d’établir la loi d’Arc sinus de Paul Levy ou la loi uniforme de Gnedenko (cf. chap. 9). Considérons un quadrillage (fig. 6) situé dans le premier quadrant x 閭 0, y 閭 0 et dénombrons les chemins analogues aux précédents (constitués de traits horizontaux et verticaux) partant de O et aboutissant sur la droite D d’équation x + y = 2n , c’est-à-dire ayant 2n segments, et situés au-dessous de la droite x = y qu’ils peuvent éventuellement toucher (sans la traverser). Soit Dn le nombre de ces chemins. On montre que Dn = Cn 2n , autrement dit qu’il y a autant de tels chemins que de chemins joignant O au point A. Prenons maintenant un cheminement où les traits horizontaux sont toujours parcourus de gauche à droite, les traits verticaux de bas en haut, comprenant toujours 2n segments, mais dans lequel 2k segments peuvent être situés au-dessus de la droite x = y . Soit Dn ,k le nombre de tels cheminements; on montre que Dn ,k = Dk Dn size=1漣 k . La formule de Stirling:
D’autres problèmes ont des solutions qui, à la limite, permettent d’établir la loi d’Arc sinus de Paul Levy ou la loi uniforme de Gnedenko (cf. chap. 9). Considérons un quadrillage (fig. 6) situé dans le premier quadrant x 閭 0, y 閭 0 et dénombrons les chemins analogues aux précédents (constitués de traits horizontaux et verticaux) partant de O et aboutissant sur la droite D d’équation x + y = 2n , c’est-à-dire ayant 2n segments, et situés au-dessous de la droite x = y qu’ils peuvent éventuellement toucher (sans la traverser). Soit Dn le nombre de ces chemins. On montre que Dn = Cn 2n , autrement dit qu’il y a autant de tels chemins que de chemins joignant O au point A. Prenons maintenant un cheminement où les traits horizontaux sont toujours parcourus de gauche à droite, les traits verticaux de bas en haut, comprenant toujours 2n segments, mais dans lequel 2k segments peuvent être situés au-dessus de la droite x = y . Soit Dn ,k le nombre de tels cheminements; on montre que Dn ,k = Dk Dn size=1漣 k . La formule de Stirling: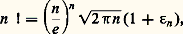 avec 﨎n0 pour n秊, donne une approximation asymptotique de n !, et, en faisant tendre n vers l’infini, on retrouve la loi d’Arc sinus. Appelons maintenant Cn ,k le nombre de tels chemins joignant O au point A(n ,n ) et ayant 2k segments au-dessus de la droite y = x . On peut établir que:
avec 﨎n0 pour n秊, donne une approximation asymptotique de n !, et, en faisant tendre n vers l’infini, on retrouve la loi d’Arc sinus. Appelons maintenant Cn ,k le nombre de tels chemins joignant O au point A(n ,n ) et ayant 2k segments au-dessus de la droite y = x . On peut établir que: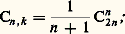
Encyclopédie Universelle. 2012.